Seaborn 接受的数据结构#
作为数据可视化库,Seaborn 需要您提供数据。本章介绍完成此任务的各种方法。Seaborn 支持几种不同的数据集格式,大多数函数接受使用来自 pandas 或 numpy 库的对象以及内置 Python 类型(如列表和字典)表示的数据。了解与这些不同选项相关的使用模式将帮助您快速为几乎任何数据集创建有用的可视化效果。
注意
截至目前(v0.13.0),此处介绍的所有选项都受大多数 seaborn 函数支持,但并非全部函数都支持。即,一些较旧的函数(例如,lmplot() 和 regplot())在其接受的内容方面更加有限。
长格式数据与宽格式数据#
Seaborn 中大多数绘图函数都针对数据向量。当将 x 绘制到 y 时,每个变量都应该是一个向量。Seaborn 接受具有以某种表格方式组织的多个向量的数据集。长格式数据表和宽格式数据表之间存在根本区别,Seaborn 将以不同的方式处理它们。
长格式数据#
长格式数据表具有以下特征
每个变量都是一列
每个观测值都是一行
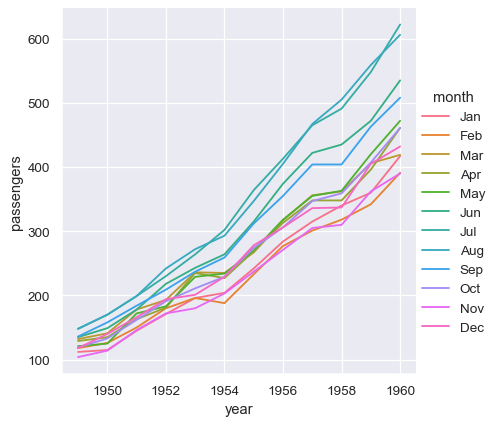
举个简单的例子,考虑“航班”数据集,它记录了从 1949 年到 1960 年每个月搭乘飞机的乘客数量。该数据集包含三个变量(年份、月份和乘客数量)
flights = sns.load_dataset("flights")
flights.head()
| 年份 | 月份 | 乘客数量 | |
|---|---|---|---|
| 0 | 1949 | 一月 | 112 |
| 1 | 1949 | 二月 | 118 |
| 2 | 1949 | 三月 | 132 |
| 3 | 1949 | 四月 | 129 |
| 4 | 1949 | 五月 | 121 |
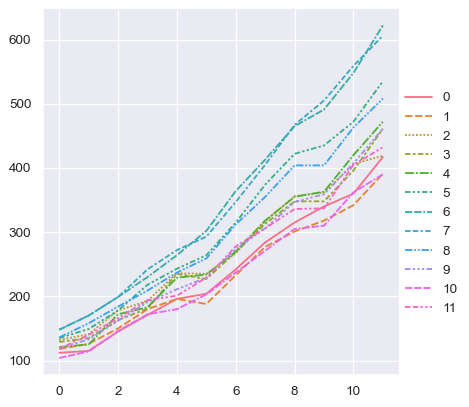
对于长格式数据,表中的列通过明确将其分配给其中一个变量来在绘图中赋予角色。例如,制作每月乘客数量按年份的绘图如下所示
sns.relplot(data=flights, x="year", y="passengers", hue="month", kind="line")
长格式数据的优势在于它非常适合这种显式指定绘图。它可以适应任意复杂程度的数据集,只要变量和观测值可以明确定义即可。但这种格式需要一些时间来习惯,因为它通常不是人们心中对数据的模型。
宽格式数据#
对于简单的数据集,人们往往更容易想到数据在电子表格中显示的方式,其中列和行包含不同变量的级别。例如,我们可以通过“透视”航班数据集将其转换为宽格式组织,以便每列都包含每个月按年份的时序
flights_wide = flights.pivot(index="year", columns="month", values="passengers")
flights_wide.head()
| 月份 | 一月 | 二月 | 三月 | 四月 | 五月 | 六月 | 七月 | 八月 | 九月 | 十月 | 十一月 | 十二月 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 年份 | ||||||||||||
| 1949 | 112 | 118 | 132 | 129 | 121 | 135 | 148 | 148 | 136 | 119 | 104 | 118 |
| 1950 | 115 | 126 | 141 | 135 | 125 | 149 | 170 | 170 | 158 | 133 | 114 | 140 |
| 1951 | 145 | 150 | 178 | 163 | 172 | 178 | 199 | 199 | 184 | 162 | 146 | 166 |
| 1952 | 171 | 180 | 193 | 181 | 183 | 218 | 230 | 242 | 209 | 191 | 172 | 194 |
| 1953 | 196 | 196 | 236 | 235 | 229 | 243 | 264 | 272 | 237 | 211 | 180 | 201 |
这里我们有相同的三个变量,但它们是不同的组织方式。此数据集中的变量链接到表的维度,而不是命名字段。每个观测值都由表中单元格的值以及该单元格相对于行和列索引的坐标定义。
对于长格式数据,我们可以通过变量名访问数据集中的变量。宽格式数据并非如此。尽管如此,由于表维度与数据集中的变量之间存在明确的关联,因此 Seaborn 能够在绘图中为这些变量分配角色。
注意
当 x 和 y 均未被分配时,Seaborn 将 data 的参数视为宽格式。
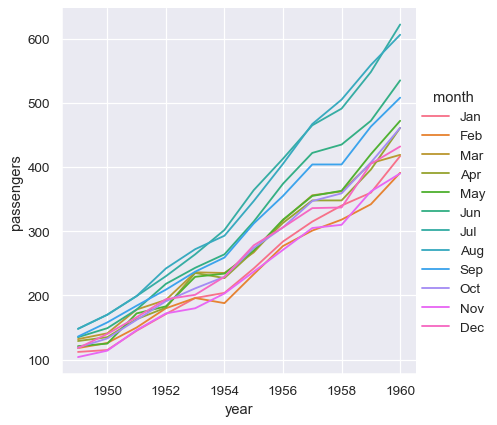
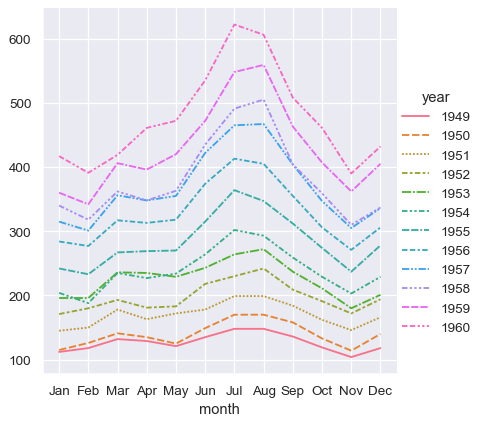
sns.relplot(data=flights_wide, kind="line")
此绘图与之前的绘图非常相似。Seaborn 已将数据框的索引分配给 x,将数据框的值分配给 y,并为每个月绘制了一条单独的线。但是,这两个绘图之间存在明显的区别。当数据集经历了将长格式转换为宽格式的“透视”操作时,有关值含义的信息丢失了。因此,没有 y 轴标签。(这些线也带有破折线,因为 relplot() 已将列变量映射到 hue 和 style 语义,以提高绘图的可访问性。我们没有在长格式情况下这样做,但可以通过设置 style="month" 来实现)。
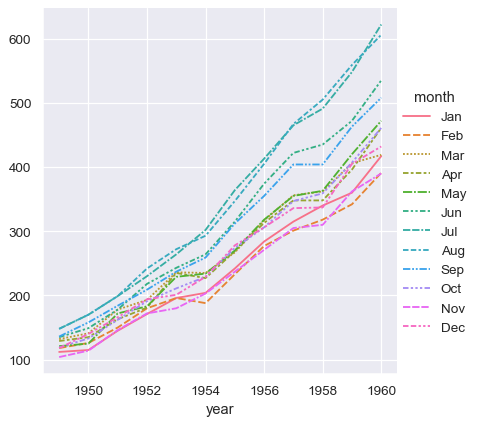
到目前为止,在使用宽格式数据时,我们输入的字符要少得多,并且制作了几乎相同的绘图。这似乎更容易!但长格式数据的一个重要优势是,一旦您将数据以正确的格式表示,您就无需再考虑其结构。您可以通过仅考虑其中包含的变量来设计绘图。例如,要绘制代表每个年份每月时间序列的线,只需重新分配变量即可
sns.relplot(data=flights, x="month", y="passengers", hue="year", kind="line")
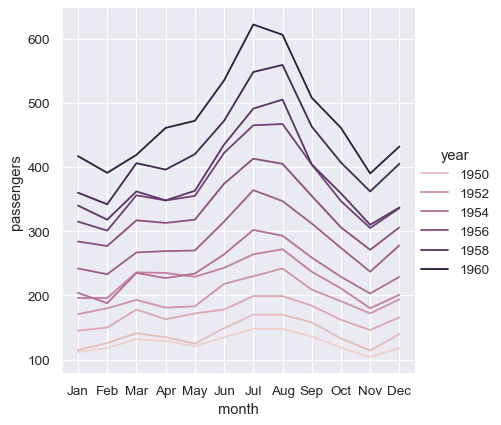
为了使用宽格式数据集实现相同的重新映射,我们需要转置表格
sns.relplot(data=flights_wide.transpose(), kind="line")
(此示例还说明了另一个问题,即 Seaborn 当前将宽格式数据集中的列变量视为分类变量,无论其数据类型如何,而长格式变量是数值的,因此分配了定量颜色调色板和图例。这在将来可能会改变)。
显式变量分配的缺失也意味着每个绘图类型都需要定义宽格式数据维度与绘图中角色之间固定的映射。由于此自然映射可能因绘图类型而异,因此使用宽格式数据时,结果的可预测性较低。例如,分类 绘图将表的列维度分配给 x,然后跨行进行聚合(忽略索引)
sns.catplot(data=flights_wide, kind="box")
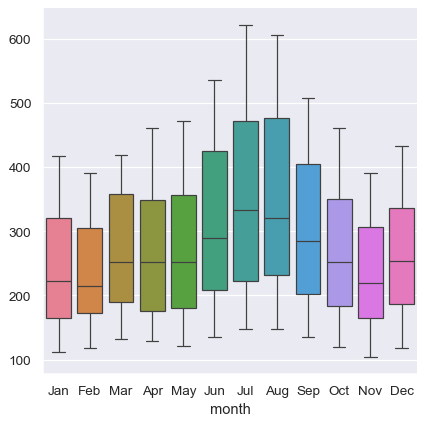
当使用 pandas 表示宽格式数据时,您仅限于几个变量(不超过三个)。这是因为 Seaborn 不使用多级索引信息,而 pandas 使用多级索引信息来表示表格格式中的其他变量。 xarray 项目提供了带标签的 N 维数组对象,可以将其视为将宽格式数据泛化到更高维度。目前,Seaborn 不直接支持来自 xarray 的对象,但可以使用 to_pandas 方法将其转换为长格式 pandas.DataFrame,然后像任何其他长格式数据集一样在 seaborn 中绘制。
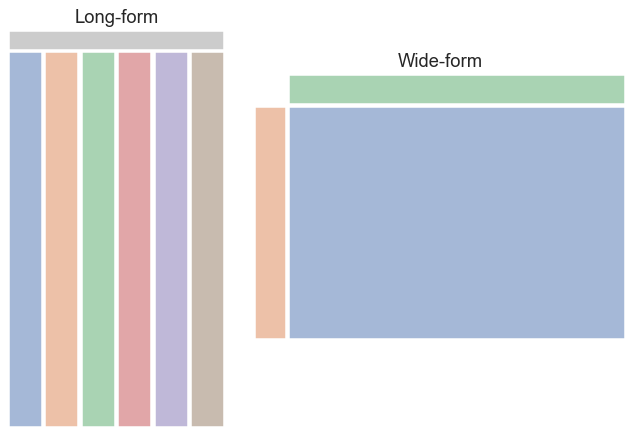
总之,我们可以认为长格式和宽格式数据集看起来像这样
杂乱数据#
许多数据集无法使用长格式或宽格式规则进行明确解释。如果明显是长格式或宽格式的数据集是 “整齐的”,我们可能会说这些更含糊不清的数据集是“杂乱的”。在杂乱的数据集中,变量既不能通过键也不能通过表的维度来唯一定义。这通常发生在重复测量数据中,其中自然地组织表,使每行对应于数据收集的单位。考虑来自心理学实验的这个简单数据集,其中 20 个受试者执行了一项记忆任务,他们在该任务中学习了字谜,同时他们的注意力要么分散要么集中
anagrams = sns.load_dataset("anagrams")
anagrams
| 受试者 ID | 注意力 | 数字 1 | 数字 2 | 数字 3 | |
|---|---|---|---|---|---|
| 0 | 1 | 分散 | 2 | 4.0 | 7 |
| 1 | 2 | 分散 | 3 | 4.0 | 5 |
| 2 | 3 | 分散 | 3 | 5.0 | 6 |
| 3 | 4 | 分散 | 5 | 7.0 | 5 |
| 4 | 5 | 分散 | 4 | 5.0 | 8 |
| 5 | 6 | 分散 | 5 | 5.0 | 6 |
| 6 | 7 | 分散 | 5 | 4.5 | 6 |
| 7 | 8 | 分散 | 5 | 7.0 | 8 |
| 8 | 9 | 分散 | 2 | 3.0 | 7 |
| 9 | 10 | 分散 | 6 | 5.0 | 6 |
| 10 | 11 | 集中 | 6 | 5.0 | 6 |
| 11 | 12 | 集中 | 8 | 9.0 | 8 |
| 12 | 13 | 集中 | 6 | 5.0 | 9 |
| 13 | 14 | 集中 | 8 | 8.0 | 7 |
| 14 | 15 | 集中 | 8 | 8.0 | 7 |
| 15 | 16 | 集中 | 6 | 8.0 | 7 |
| 16 | 17 | 集中 | 7 | 7.0 | 6 |
| 17 | 18 | 集中 | 7 | 8.0 | 6 |
| 18 | 19 | 集中 | 5 | 6.0 | 6 |
| 19 | 20 | 集中 | 6 | 6.0 | 5 |
注意力变量是受试者间的,但还存在受试者内变量:字谜的可能解数量,从 1 到 3 不等。因变量是记忆表现得分。这两个变量(数字和得分)在多个列中共同编码。因此,整个数据集既不是明显的长格式也不是明显的宽格式。
我们如何告诉 Seaborn 绘制平均得分作为注意力和解数量的函数?首先,我们需要将数据强制转换为我们两种结构之一。让我们将其转换为整齐的长格式表,以便每个变量都是一列,每行都是一个观测值。我们可以使用 pandas.DataFrame.melt() 方法来完成此任务
anagrams_long = anagrams.melt(id_vars=["subidr", "attnr"], var_name="solutions", value_name="score")
anagrams_long.head()
| 受试者 ID | 注意力 | 解 | 得分 | |
|---|---|---|---|---|
| 0 | 1 | 分散 | 数字 1 | 2.0 |
| 1 | 2 | 分散 | 数字 1 | 3.0 |
| 2 | 3 | 分散 | 数字 1 | 3.0 |
| 3 | 4 | 分散 | 数字 1 | 5.0 |
| 4 | 5 | 分散 | 数字 1 | 4.0 |
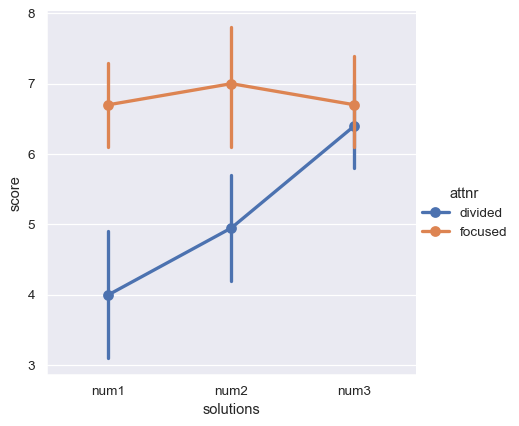
现在我们可以绘制我们想要的绘图
sns.catplot(data=anagrams_long, x="solutions", y="score", hue="attnr", kind="point")
进一步阅读和要点#
有关表格数据结构的更详细讨论,您可以阅读 Hadley Whickham 的 “整齐数据” 文章。请注意,Seaborn 使用的概念集与文章中定义的概念集略有不同。虽然文章将整齐性与长格式结构相关联,但我们已经区分了“整齐宽格式”数据(其中数据集中的变量与表的维度之间存在明确的映射)和“杂乱数据”(其中不存在这种映射)。
长格式结构具有明显的优势。它允许您通过将数据集中的变量显式分配给绘图中的角色来创建图形,并且您可以使用超过三个变量。如果可能,尝试使用长格式结构来表示数据,以便进行认真的分析。Seaborn 文档中的大多数示例都将使用长格式数据。但在某些情况下,如果将数据集保持为宽格式更自然,请记住 Seaborn 仍然有用。
可视化长格式数据的选项#
虽然长格式数据有明确的定义,但 Seaborn 在内存中数据结构的组织方式上相当灵活。 本文档中其余示例通常使用 pandas.DataFrame 对象,并通过将它们的列名分配给绘图中的变量来引用其中的变量。 但也可以将向量存储在 Python 字典或实现该接口的类中。
flights_dict = flights.to_dict()
sns.relplot(data=flights_dict, x="year", y="passengers", hue="month", kind="line")
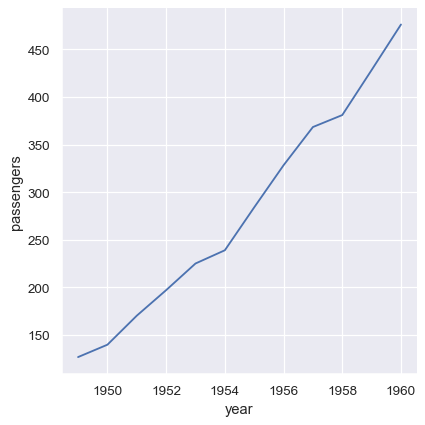
许多 pandas 操作,如 group-by 的 split-apply-combine 操作,将生成一个 dataframe,其中信息已从输入 dataframe 的列移动到输出的索引。 只要保留了名称,您仍然可以像往常一样引用数据。
flights_avg = flights.groupby("year").mean(numeric_only=True)
sns.relplot(data=flights_avg, x="year", y="passengers", kind="line")
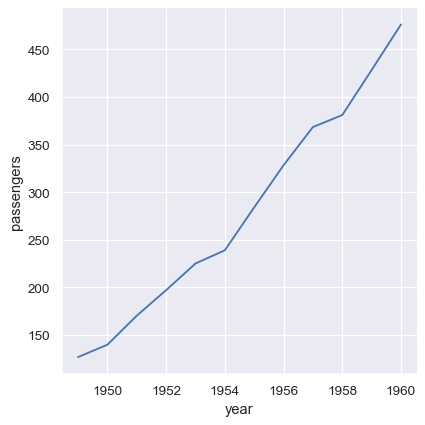
此外,可以将数据向量直接作为参数传递给 x、y 和其他绘图变量。 如果这些向量是 pandas 对象,则 name 属性将用于标记绘图。
year = flights_avg.index
passengers = flights_avg["passengers"]
sns.relplot(x=year, y=passengers, kind="line")
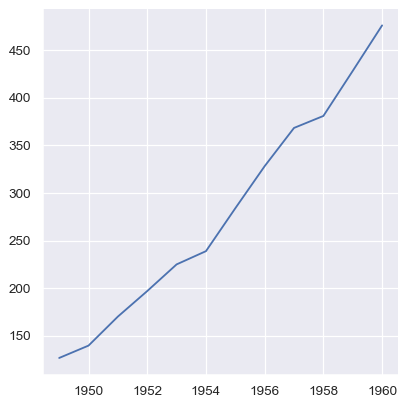
Numpy 数组和其他实现 Python 序列接口的对象也可以使用,但如果它们没有名称,则在没有进一步调整的情况下,绘图不会提供足够的信息。
sns.relplot(x=year.to_numpy(), y=passengers.to_list(), kind="line")
可视化宽格式数据的选项#
传递宽格式数据的选项更加灵活。 与长格式数据一样,pandas 对象更可取,因为可以利用名称(在某些情况下,包括索引)信息。 但本质上,任何可以被视为单个向量或向量集合的格式都可以传递给 data,通常可以构建有效的绘图。
我们上面看到的示例使用了矩形 pandas.DataFrame,可以将其视为其列的集合。 dict 或 pandas 对象列表也可以使用,但我们将丢失轴标签。
flights_wide_list = [col for _, col in flights_wide.items()]
sns.relplot(data=flights_wide_list, kind="line")
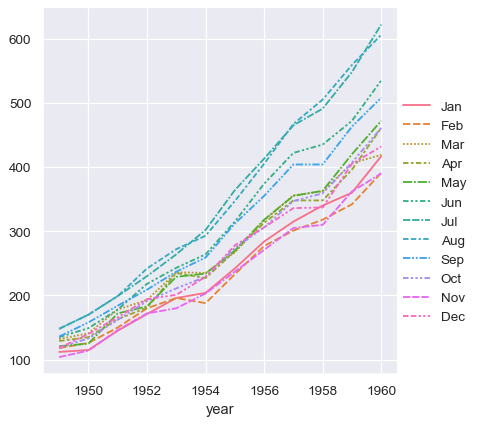
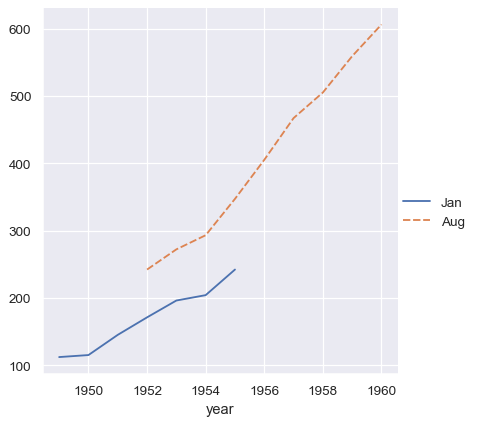
集合中的向量不必具有相同的长度。 如果它们有 index,它将用于对齐它们。
two_series = [flights_wide.loc[:1955, "Jan"], flights_wide.loc[1952:, "Aug"]]
sns.relplot(data=two_series, kind="line")
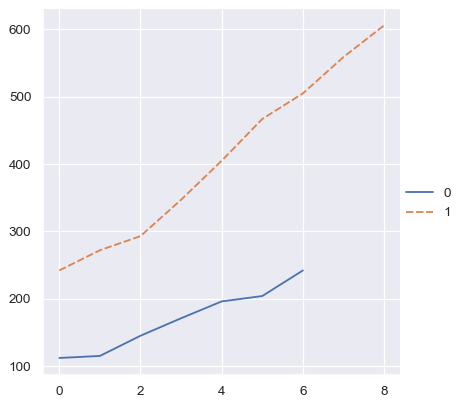
而对于 numpy 数组或简单的 Python 序列,将使用序数索引。
two_arrays = [s.to_numpy() for s in two_series]
sns.relplot(data=two_arrays, kind="line")
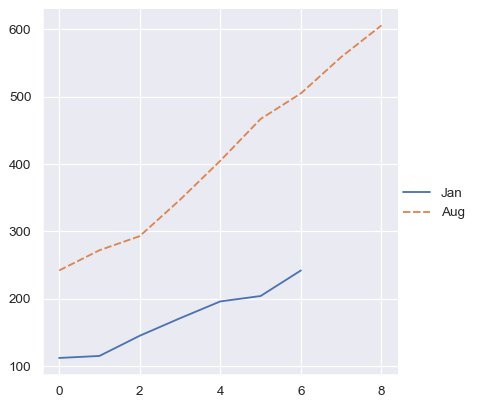
但这样一个向量的字典至少会使用键。
two_arrays_dict = {s.name: s.to_numpy() for s in two_series}
sns.relplot(data=two_arrays_dict, kind="line")
矩形 numpy 数组被视为没有索引信息的 dataframe,因此它们被视为列向量的集合。 请注意,这与 numpy 索引操作的工作方式不同,在 numpy 索引操作中,单个索引器将访问一行。 但它与 pandas 如何将数组转换为 dataframe 或 matplotlib 如何绘制数组是一致的。
flights_array = flights_wide.to_numpy()
sns.relplot(data=flights_array, kind="line")