Seaborn 简介#
Seaborn 是一个用于在 Python 中制作统计图形的库。它建立在 matplotlib 之上,并与 pandas 数据结构紧密集成。
Seaborn 可以帮助您探索和理解数据。它的绘图函数在包含整个数据集的数据框和数组上运行,并在内部执行必要的语义映射和统计聚合以生成信息丰富的绘图。它面向数据集的声明式 API 使您能够专注于绘图的不同元素的含义,而不是如何绘制它们的细节。
以下是一个 Seaborn 可以执行的操作示例
# Import seaborn
import seaborn as sns
# Apply the default theme
sns.set_theme()
# Load an example dataset
tips = sns.load_dataset("tips")
# Create a visualization
sns.relplot(
data=tips,
x="total_bill", y="tip", col="time",
hue="smoker", style="smoker", size="size",
)
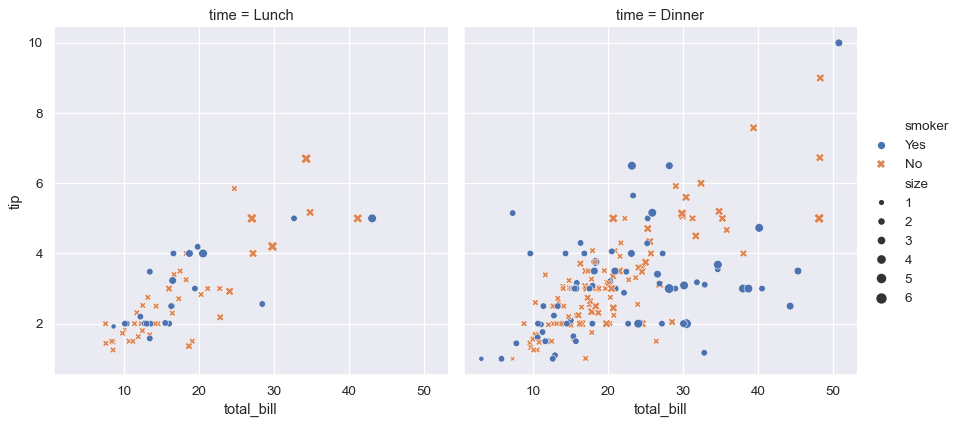
这里发生了一些事情。让我们逐一介绍。
# Import seaborn
import seaborn as sns
Seaborn 是我们在这个简单示例中唯一需要导入的库。按照惯例,它使用缩写 sns 导入。
在幕后,Seaborn 使用 matplotlib 绘制其图形。对于交互式工作,建议在 matplotlib 模式 下使用 Jupyter/IPython 接口,否则您必须在要查看图形时调用 matplotlib.pyplot.show()。
# Apply the default theme
sns.set_theme()
这将使用 matplotlib rcParam 系统,并影响所有 matplotlib 图形的显示方式,即使您不是使用 seaborn 制作的。除了默认主题之外,还有 其他几个选项,您可以独立控制图形的样式和缩放比例,以便快速将您的工作在演示环境之间转换(例如,制作一个图形版本,该版本在演讲中投影时具有可读的字体)。如果您喜欢 matplotlib 默认值或偏好其他主题,您可以跳过此步骤,仍然可以使用 seaborn 绘图函数。
# Load an example dataset
tips = sns.load_dataset("tips")
文档中的大多数代码都将使用 load_dataset() 函数快速访问示例数据集。这些数据集没有什么特别之处:它们只是 pandas 数据框,我们可以使用 pandas.read_csv() 加载它们,或者手工构建它们。文档中的大多数示例将使用 pandas 数据框指定数据,但 Seaborn 对其接受的 数据结构 非常灵活。
# Create a visualization
sns.relplot(
data=tips,
x="total_bill", y="tip", col="time",
hue="smoker", style="smoker", size="size",
)
该图使用对 seaborn 函数 relplot() 的一次调用显示了 tips 数据集中五个变量之间的关系。请注意,我们只提供了变量的名称及其在绘图中的作用。与直接使用 matplotlib 不同,不必根据颜色值或标记代码指定绘图元素的属性。在幕后,seaborn 处理了从数据框中的值到 matplotlib 理解的参数的转换。这种声明式方法使您能够专注于要回答的问题,而不是如何控制 matplotlib 的细节。
用于统计图形的高级 API#
没有一种普遍最好的方法来可视化数据。不同的问题最好用不同的图形来回答。Seaborn 通过使用一致的面向数据集的 API 使在不同的视觉表示之间轻松切换成为可能。
函数 relplot() 的命名方式是因为它旨在可视化许多不同的统计关系。虽然散点图通常很有效,但其中一个变量代表时间度量的关系最好用直线来表示。函数 relplot() 具有一个方便的 kind 参数,可以让您轻松地切换到这种替代表示。
dots = sns.load_dataset("dots")
sns.relplot(
data=dots, kind="line",
x="time", y="firing_rate", col="align",
hue="choice", size="coherence", style="choice",
facet_kws=dict(sharex=False),
)
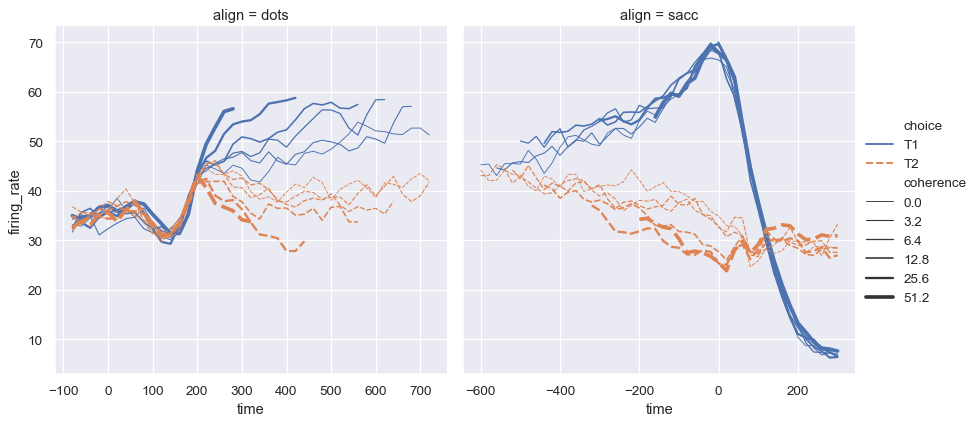
请注意,size 和 style 参数如何在散点图和直线图中使用,但它们对两种可视化的影响不同:在散点图中更改标记区域和符号,而在直线图中更改线宽和虚线。我们不需要记住这些细节,从而让我们专注于图形的整体结构以及我们希望它传达的信息。
统计估计#
通常,我们对一个变量的平均值作为其他变量的函数感兴趣。许多 seaborn 函数会自动执行回答这些问题所需的统计估计。
fmri = sns.load_dataset("fmri")
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal", col="region",
hue="event", style="event",
)
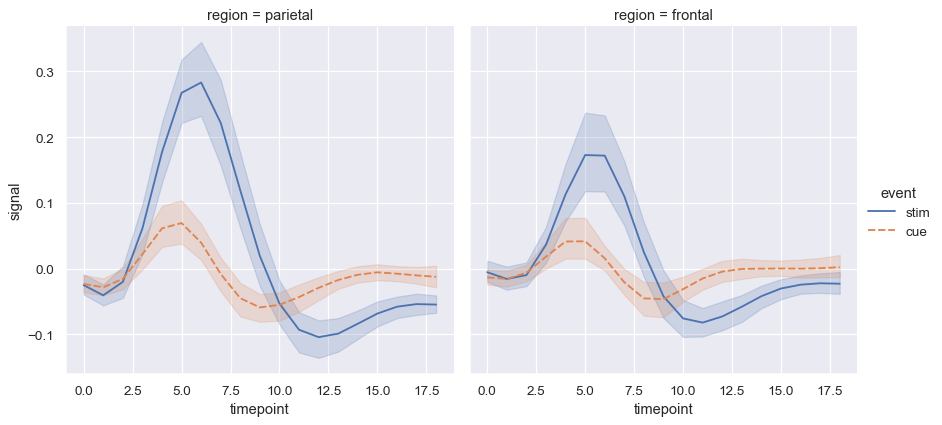
当估计统计值时,seaborn 将使用引导法来计算置信区间并绘制误差条,表示估计的不确定性。
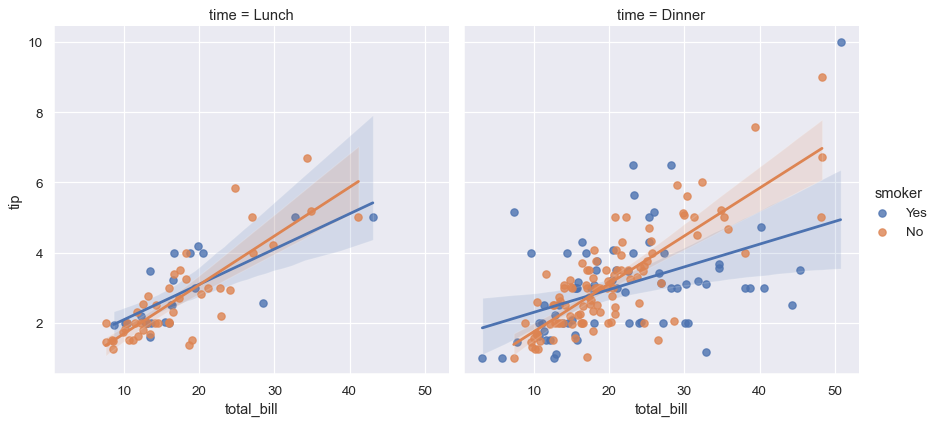
seaborn 中的统计估计超出了描述性统计。例如,可以使用 lmplot() 通过包含线性回归模型(及其不确定性)来增强散点图。
sns.lmplot(data=tips, x="total_bill", y="tip", col="time", hue="smoker")
分布表示#
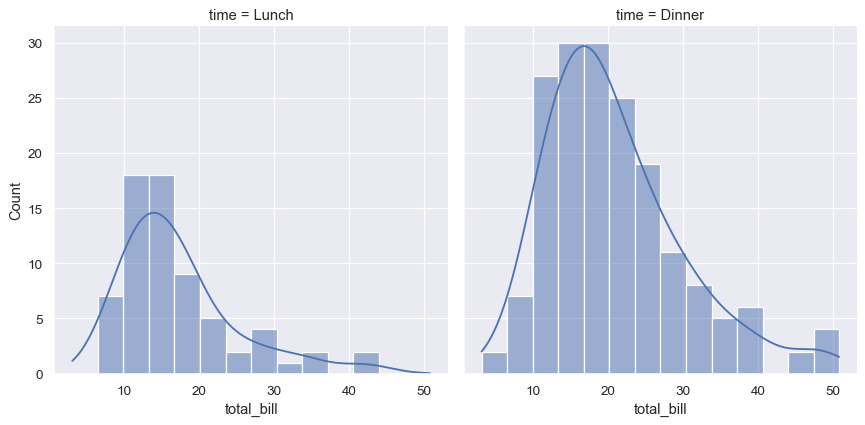
统计分析需要了解数据集中变量的分布。seaborn 函数 displot() 支持几种可视化分布的方法。这些方法包括直方图等经典技术,以及核密度估计等计算密集型方法。
sns.displot(data=tips, x="total_bill", col="time", kde=True)
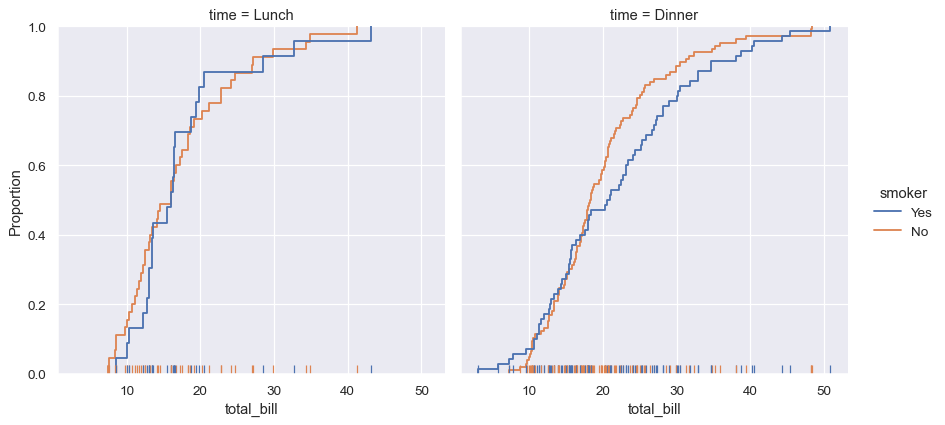
Seaborn 还尝试推广功能强大但不太熟悉的技术,例如计算和绘制数据的经验累积分布函数。
sns.displot(data=tips, kind="ecdf", x="total_bill", col="time", hue="smoker", rug=True)
分类数据的绘图#
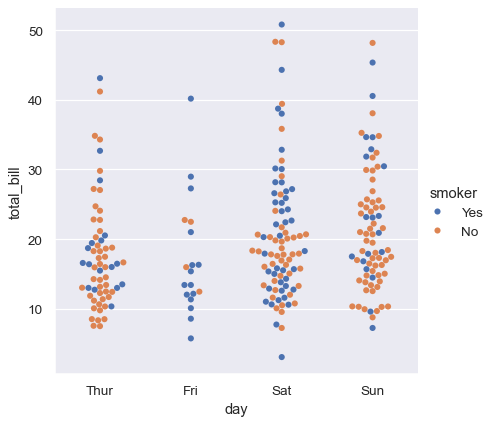
seaborn 中的几个专用绘图类型面向可视化分类数据。它们可以通过 catplot() 访问。这些绘图提供不同级别的粒度。在最精细的级别,您可能希望通过绘制“swarm”图来查看每个观察结果:一个散点图,它沿分类轴调整点的坐标,使它们不会重叠。
sns.catplot(data=tips, kind="swarm", x="day", y="total_bill", hue="smoker")
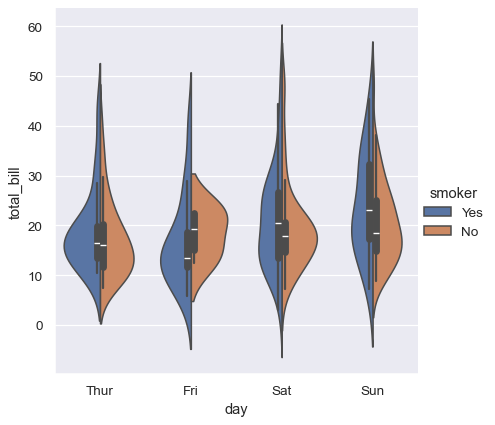
或者,您可以使用核密度估计来表示点采样的基础分布。
sns.catplot(data=tips, kind="violin", x="day", y="total_bill", hue="smoker", split=True)
或者,您只需显示每个嵌套类别中的平均值及其置信区间。
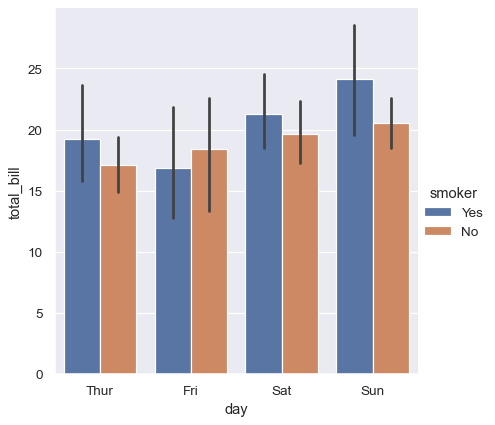
sns.catplot(data=tips, kind="bar", x="day", y="total_bill", hue="smoker")
复杂数据集的多元视图#
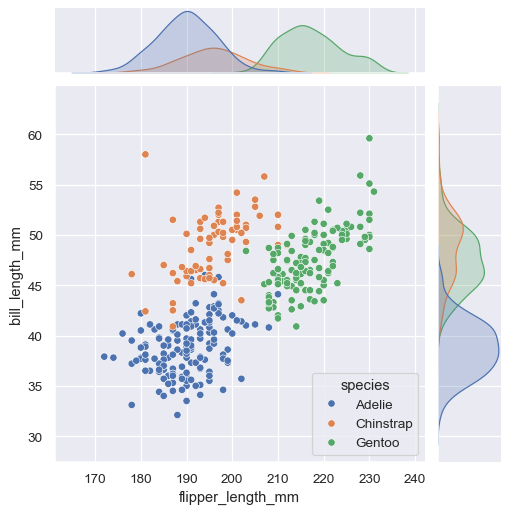
一些 seaborn 函数结合了多种类型的绘图,以便快速给出数据集的信息摘要。其中一个 jointplot() 专注于单个关系。它绘制了两个变量之间的联合分布以及每个变量的边缘分布。
penguins = sns.load_dataset("penguins")
sns.jointplot(data=penguins, x="flipper_length_mm", y="bill_length_mm", hue="species")
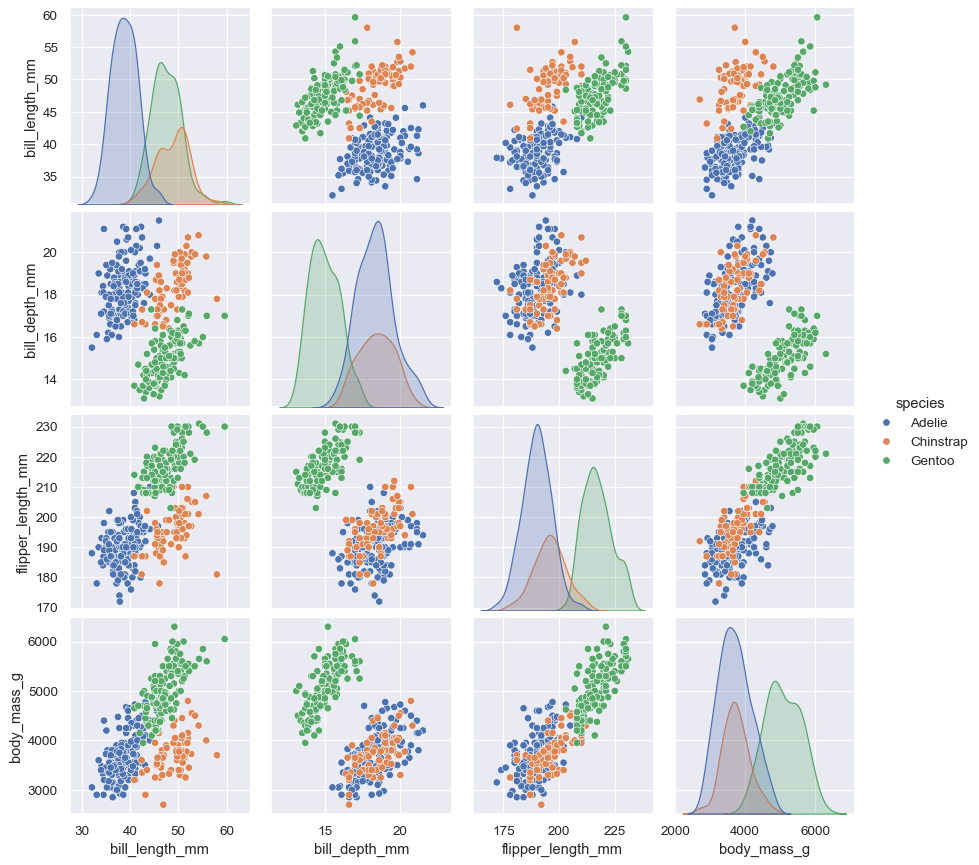
另一个,pairplot(),则更广泛地查看:它显示了所有成对关系以及每个变量的联合分布和边缘分布,分别。
sns.pairplot(data=penguins, hue="species")
用于构建图形的低级工具#
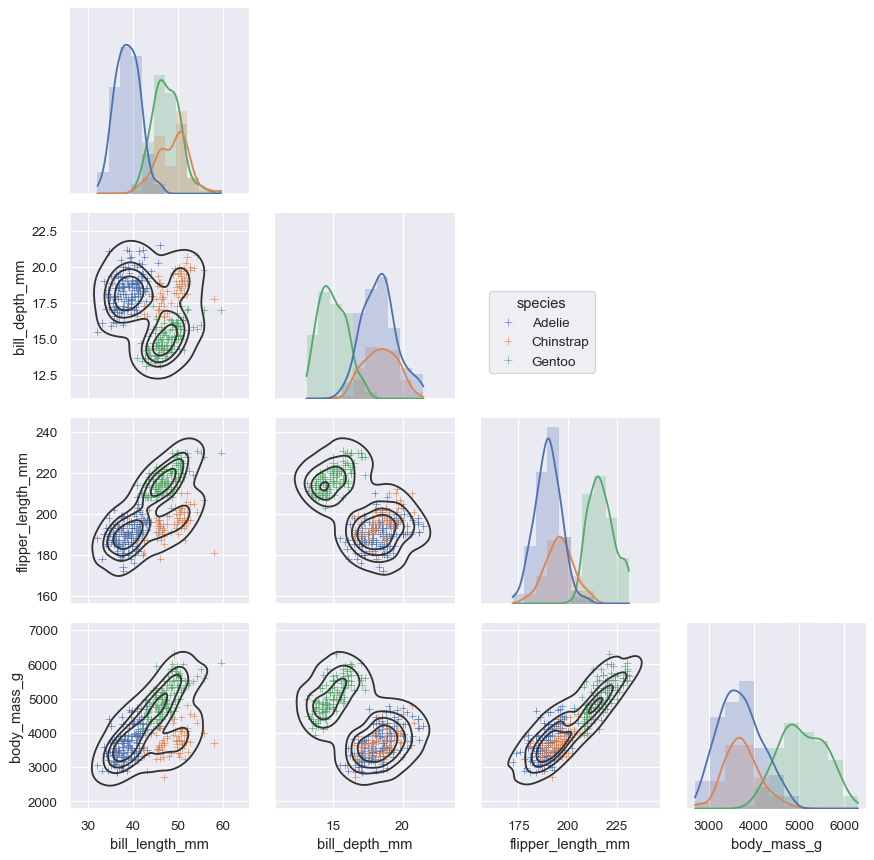
这些工具通过将 轴级 绘图函数与管理图形布局的对象结合使用,将数据集的结构链接到 轴网格。这两个元素都是公共 API 的一部分,您可以直接使用它们来创建复杂图形,只需几行代码。
g = sns.PairGrid(penguins, hue="species", corner=True)
g.map_lower(sns.kdeplot, hue=None, levels=5, color=".2")
g.map_lower(sns.scatterplot, marker="+")
g.map_diag(sns.histplot, element="step", linewidth=0, kde=True)
g.add_legend(frameon=True)
g.legend.set_bbox_to_anchor((.61, .6))
有见地的默认值和灵活的自定义#
Seaborn 使用单个函数调用创建完整的图形:在可能的情况下,它的函数会自动添加信息丰富的轴标签和图例,以解释绘图中的语义映射。
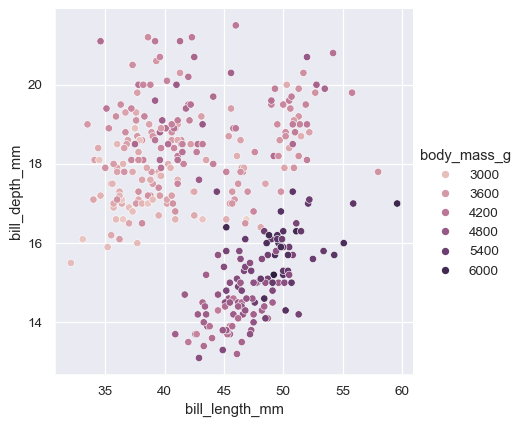
在许多情况下,seaborn 还将根据数据的特征为其参数选择默认值。例如,我们迄今为止看到的 颜色映射 使用不同的色调(蓝色、橙色,有时还有绿色)来表示分配给 hue 的分类变量的不同级别。当映射数字变量时,某些函数将切换到连续渐变。
sns.relplot(
data=penguins,
x="bill_length_mm", y="bill_depth_mm", hue="body_mass_g"
)
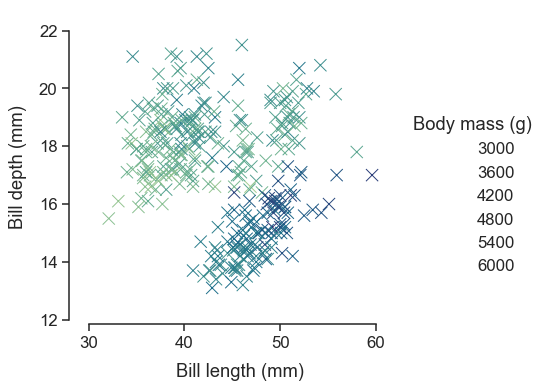
当您准备好共享或发布您的工作时,您可能希望将图形修饰到超出默认值的程度。Seaborn 允许进行多个级别的自定义。它定义了多个内置的 主题,这些主题适用于所有图形,它的函数具有标准化的参数,可以修改每个图形的语义映射,并且其他关键字参数传递给底层的 matplotlib 艺术家,允许更细粒度的控制。创建图形后,可以通过 seaborn API 和通过下降到 matplotlib 层进行细粒度的调整来修改其属性。
sns.set_theme(style="ticks", font_scale=1.25)
g = sns.relplot(
data=penguins,
x="bill_length_mm", y="bill_depth_mm", hue="body_mass_g",
palette="crest", marker="x", s=100,
)
g.set_axis_labels("Bill length (mm)", "Bill depth (mm)", labelpad=10)
g.legend.set_title("Body mass (g)")
g.figure.set_size_inches(6.5, 4.5)
g.ax.margins(.15)
g.despine(trim=True)
与 matplotlib 的关系#
Seaborn 与 matplotlib 的集成允许您在 matplotlib 支持的许多环境中使用它,包括笔记本中的探索性分析、GUI 应用程序中的实时交互以及多种光栅和矢量格式的存档输出。
虽然你可以仅使用 seaborn 函数来提高工作效率,但要完全自定义图形,你需要了解一些 matplotlib 的概念和 API。对于 seaborn 的新用户来说,学习曲线的一个方面是了解何时需要降级到 matplotlib 层才能实现特定自定义。另一方面,来自 matplotlib 的用户会发现他们的很多知识都可以迁移过来。
Matplotlib 有一个全面且强大的 API;几乎可以更改图形的任何属性来满足你的喜好。seaborn 的高级界面和 matplotlib 的深度可定制性相结合,让你既可以快速探索数据,又可以创建可定制成 出版物质量 的最终产品。
下一步#
你可以选择下一步做什么。你可能首先想学习如何 安装 seaborn。完成之后,你可以浏览 示例库,以更广泛地了解 seaborn 可以生成哪些类型的图形。或者你可以通读 用户指南和教程,以便更深入地了解不同的工具及其设计目的。如果你心中有一个特定的绘图,并且想知道如何绘制它,你可以查看 API 参考,它记录了每个函数的参数并展示了许多示例来说明用法。