seaborn.relplot#
- seaborn.relplot(data=None, *, x=None, y=None, hue=None, size=None, style=None, units=None, weights=None, row=None, col=None, col_wrap=None, row_order=None, col_order=None, palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None, size_norm=None, markers=None, dashes=None, style_order=None, legend='auto', kind='scatter', height=5, aspect=1, facet_kws=None, **kwargs)#
在 FacetGrid 上绘制关系图的图级接口。
此函数提供对几个不同的轴级函数的访问,这些函数显示了两个变量之间的关系,并使用语义映射来识别子集。
kind参数选择要使用的底层轴级函数scatterplot()(使用kind="scatter";默认值)lineplot()(使用kind="line")
额外的关键字参数将传递给底层函数,因此您应该参考每个函数的文档以查看特定于类型的选项。
可以使用
hue、size和style参数显示x和y之间的关系,以用于数据的不同子集。这些参数控制使用哪些视觉语义来识别不同的子集。通过使用所有三种语义类型,可以独立地显示最多三个维度,但这种类型的绘图可能难以解释,并且通常无效。使用冗余语义(即对同一变量同时使用hue和style)可以帮助使图形更易访问。有关更多信息,请参阅 教程。
如果存在
hue(以及在较小程度上,size)语义,则其默认处理方式取决于变量是否被推断为表示“数值”或“类别”数据。特别是,数值变量默认情况下使用连续色图表示,并且图例条目显示带有一定值(可能存在于数据中,也可能不存在)的常规“刻度”。可以通过各种参数控制此行为,如下所述和说明。绘图后,将返回带有绘图的
FacetGrid,并且可以直接使用它来调整支持绘图的详细信息或添加其他图层。- 参数::
- data
pandas.DataFrame、numpy.ndarray、映射或序列 输入数据结构。可以分配给命名变量的向量集合(长格式),或者将在内部重新排列的宽格式数据集。
- x, y向量或
data中的键 指定 x 轴和 y 轴上位置的变量。
- hue向量或
data中的键 分组变量,将生成具有不同颜色的元素。可以是分类变量或数值变量,尽管在后一种情况下,颜色映射的行为会有所不同。
- 大小在
data中的向量或键 分组变量,将产生不同大小的元素。可以是分类变量或数值变量,但大小映射在后一种情况下会有不同的行为。
- 样式在
data中的向量或键 分组变量,将产生不同样式的元素。可以具有数值数据类型,但始终被视为分类变量。
- 单位在
data中的向量或键 识别采样单位的分组变量。使用时,将为每个单位绘制单独的线,并具有相应的语义,但不会添加图例条目。在不需要确切标识时,可用于显示实验重复的分布。
- 权重在
data中的向量或键 用于计算加权估计的数据值或列。请注意,使用权重当前将统计量选择限制为“均值”估计量和“ci”误差条。
- 行,列在
data中的向量或键 定义在不同方面绘制子集的变量。
- col_wrapint
将列变量“包裹”在该宽度,以便列方面跨越多行。与
row方面不兼容。- row_order,col_order字符串列表
组织网格的行和/或列的顺序,否则顺序将从数据对象推断。
- 调色板字符串、列表、字典或
matplotlib.colors.Colormap 在映射
hue语义时选择要使用的颜色方法。字符串值传递给color_palette()。列表或字典值意味着分类映射,而颜色图对象意味着数值映射。- hue_order字符串向量
指定
hue语义的分类级别的处理和绘制顺序。- hue_norm元组或
matplotlib.colors.Normalize 一对值,用于设置数据单位中的归一化范围,或者一个对象,将从数据单位映射到 [0, 1] 区间。用法意味着数值映射。
- 大小列表、字典或元组
确定在使用
size时如何选择大小的对象。列表或字典参数应为每个唯一数据值提供一个大小,这将强制执行分类解释。参数也可以是最小值、最大值元组。- size_order列表
指定
size变量级别的出现顺序,否则它们将从数据中确定。当size变量为数值时,这并不相关。- size_norm元组或 Normalize 对象
数据单位中的归一化,用于在
size变量为数值时缩放绘图对象。- style_order列表
指定
style变量级别的出现顺序,否则它们将从数据中确定。当style变量为数值时,这并不相关。- 破折号布尔值、列表或字典
确定如何为
style变量的不同级别绘制线条的对象。设置为True将使用默认破折号代码,或者您可以传递一个破折号代码列表或一个字典,将style变量的级别映射到破折号代码。设置为False将对所有子集使用实线。破折号的指定方式与 matplotlib 中相同:一个(segment, gap)长度元组,或一个空字符串以绘制实线。- 标记布尔值、列表或字典
确定如何为
style变量的不同级别绘制标记的对象。设置为True将使用默认标记,或者您可以传递一个标记列表或一个字典,将style变量的级别映射到标记。设置为False将绘制无标记的线条。标记的指定方式与 matplotlib 中相同。- 图例“auto”、”brief”、”full” 或 False
如何绘制图例。如果为“brief”,数值
hue和size变量将用等距值的样本表示。如果为“full”,每个组都将在图例中获得一个条目。如果为“auto”,将根据级别的数量选择“brief”或“full”表示。如果为False,则不会添加图例数据,也不会绘制图例。- 种类字符串
要绘制的绘图类型,对应于 seaborn 关系绘图。选项是
"scatter"或"line"。- 高度标量
每个方面的(英寸)高度。另请参见:
aspect。- 纵横比标量
每个方面的纵横比,因此
aspect * height以英寸为单位给出每个方面的宽度。- facet_kws字典
要传递给
FacetGrid的其他关键字参数的字典。- kwargs键值对
其他关键字参数将传递给基础绘图函数。
- data
- 返回值::
FacetGrid管理一个或多个子图的对象,这些子图对应于条件数据子集,并具有方便的方法用于批处理设置轴属性。
示例
这些示例将仅说明
relplot()能够实现的功能的一部分。有关更多信息,请咨询scatterplot()和lineplot()的示例,这些示例分别在kind="scatter"或kind="line"时使用。为了说明
kind="scatter"(默认绘图样式),我们将使用“tips”数据集tips = sns.load_dataset("tips") tips.head()
total_bill tip sex smoker day time size 0 16.99 1.01 Female No Sun Dinner 2 1 10.34 1.66 Male No Sun Dinner 3 2 21.01 3.50 Male No Sun Dinner 3 3 23.68 3.31 Male No Sun Dinner 2 4 24.59 3.61 Female No Sun Dinner 4 分配
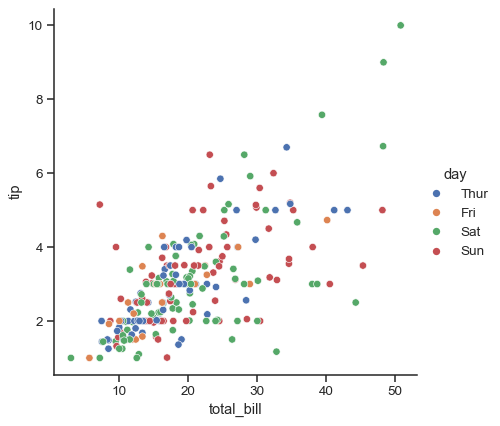
x和y以及任何语义映射变量将绘制单个绘图sns.relplot(data=tips, x="total_bill", y="tip", hue="day")
分配
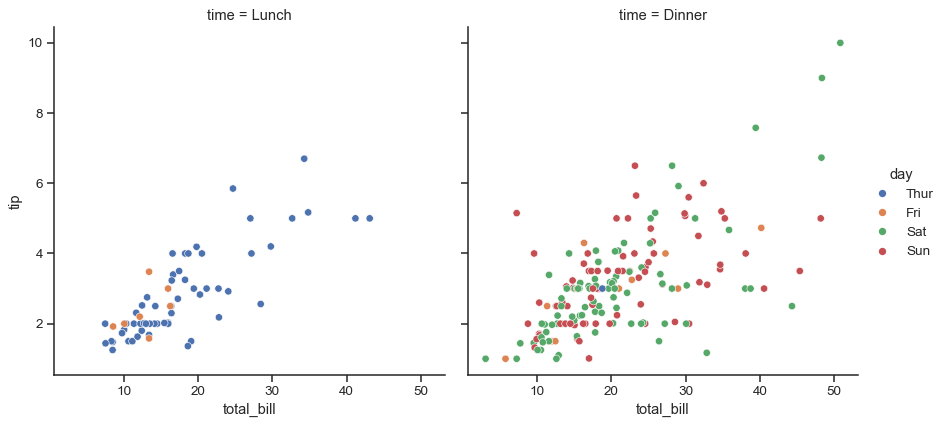
col变量将在网格的列中排列多个子图,创建一个分面图形sns.relplot(data=tips, x="total_bill", y="tip", hue="day", col="time")
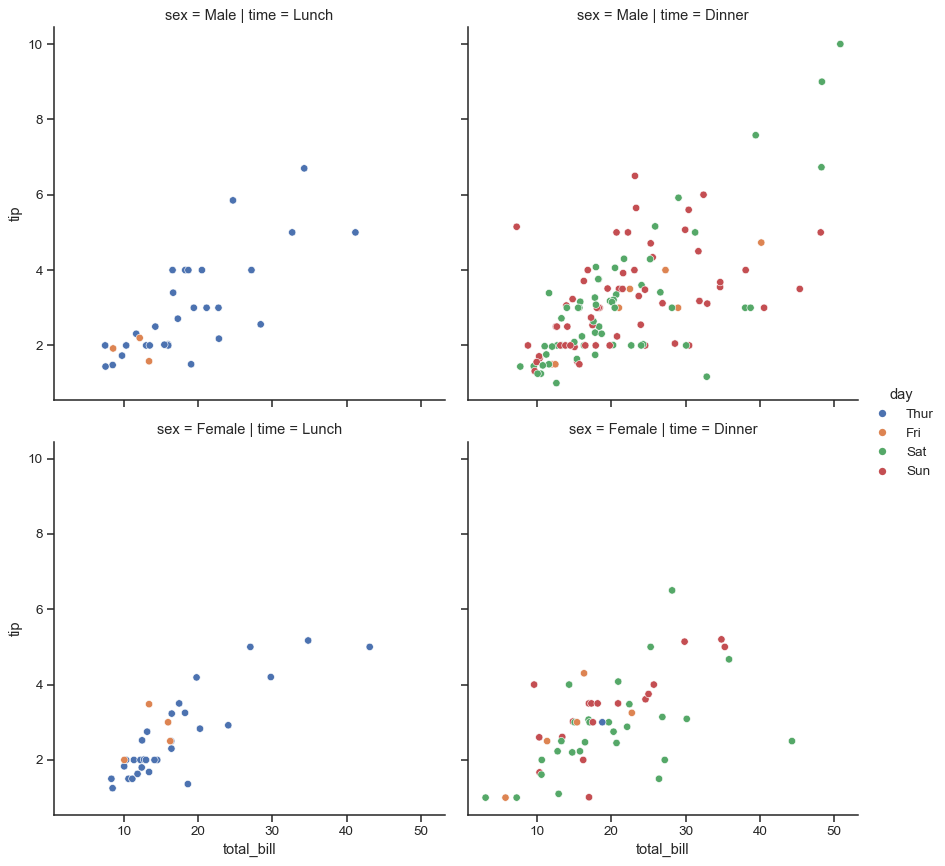
不同的变量可以分配给列和行的方面
sns.relplot(data=tips, x="total_bill", y="tip", hue="day", col="time", row="sex")
当分配给
col的变量具有许多级别时,它可以“包裹”在多行中sns.relplot(data=tips, x="total_bill", y="tip", hue="time", col="day", col_wrap=2)
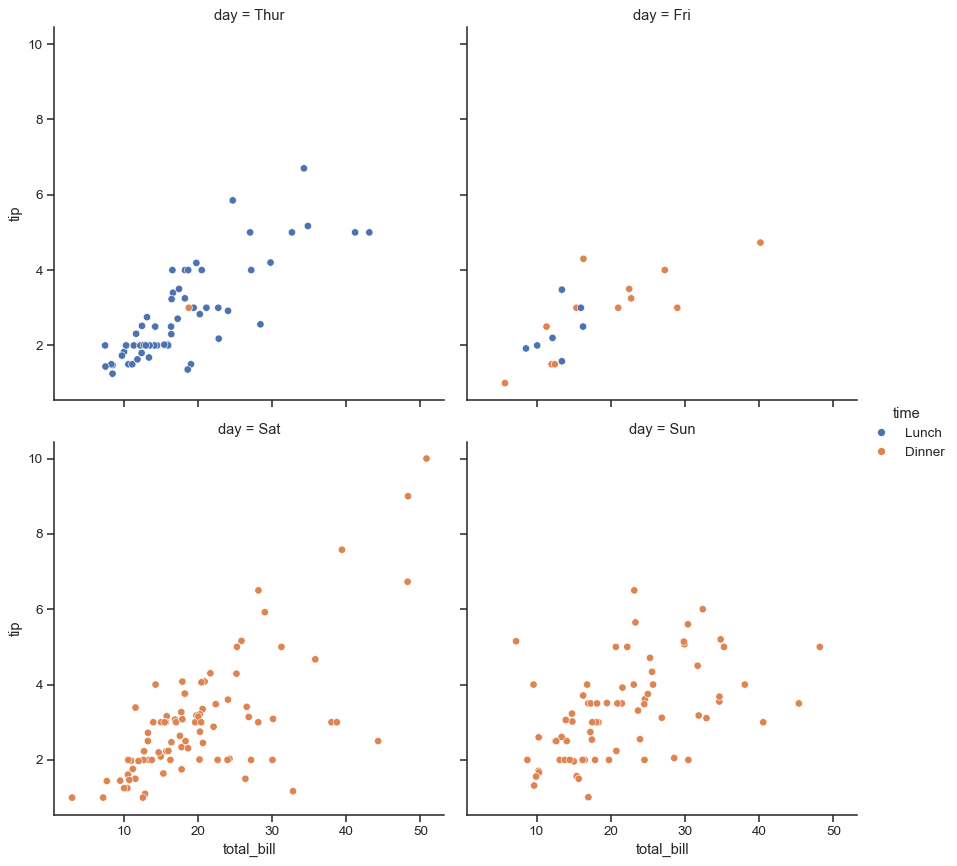
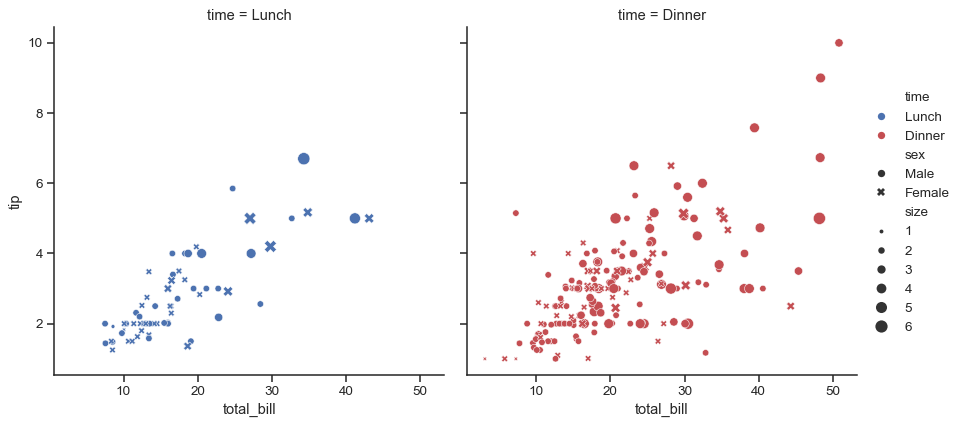
分配多个语义变量可以显示多维关系,但要注意避免制作过于复杂的绘图。
sns.relplot( data=tips, x="total_bill", y="tip", col="time", hue="time", size="size", style="sex", palette=["b", "r"], sizes=(10, 100) )
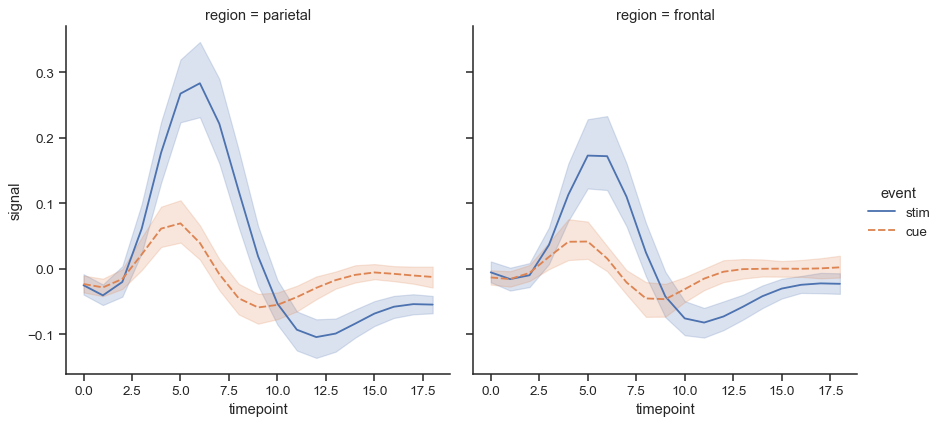
当某个变量存在自然的连续性时,显示线而不是点更有意义。要使用
lineplot()绘制图形,请设置kind="line"。我们将用“fmri”数据集说明这种效果fmri = sns.load_dataset("fmri") fmri.head()
subject timepoint event region signal 0 s13 18 stim parietal -0.017552 1 s5 14 stim parietal -0.080883 2 s12 18 stim parietal -0.081033 3 s11 18 stim parietal -0.046134 4 s10 18 stim parietal -0.037970 使用
kind="line"提供与kind="scatter"相同的语义映射灵活性,但lineplot()在绘制之前对数据进行更多转换。观察结果按其x值排序,重复观察结果被聚合。默认情况下,结果绘图显示每个单位的均值和 95% CIsns.relplot( data=fmri, x="timepoint", y="signal", col="region", hue="event", style="event", kind="line", )
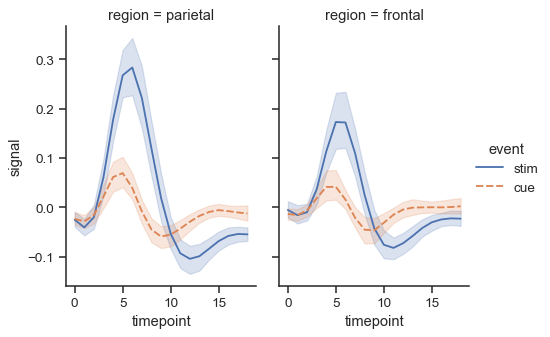
图形的大小和形状由每个单个方面的
height和aspect比例参数化sns.relplot( data=fmri, x="timepoint", y="signal", hue="event", style="event", col="region", height=4, aspect=.7, kind="line" )
由
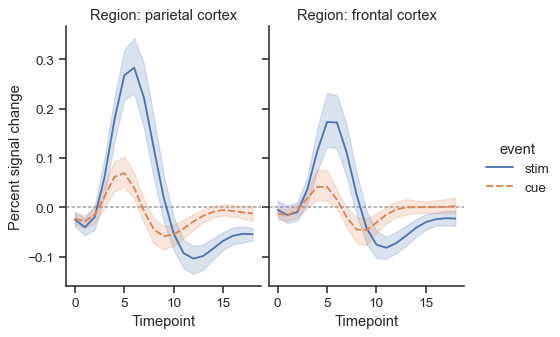
relplot()返回的对象始终是FacetGrid,它有几种方法可以让你快速调整标题、标签和绘图的其他方面g = sns.relplot( data=fmri, x="timepoint", y="signal", hue="event", style="event", col="region", height=4, aspect=.7, kind="line" ) (g.map(plt.axhline, y=0, color=".7", dashes=(2, 1), zorder=0) .set_axis_labels("Timepoint", "Percent signal change") .set_titles("Region: {col_name} cortex") .tight_layout(w_pad=0))
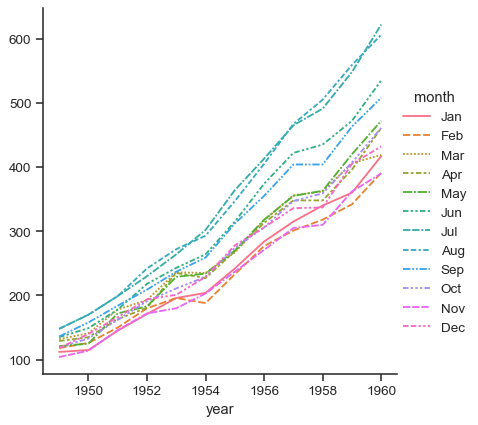
也可以使用宽格式数据和
relplot()flights_wide = ( sns.load_dataset("flights") .pivot(index="year", columns="month", values="passengers") )
在这种情况下,分面不是一个选项,但绘图仍然会利用
FacetGrid提供的外部图例sns.relplot(data=flights_wide, kind="line")