seaborn.regplot#
- seaborn.regplot(data=None, *, x=None, y=None, x_estimator=None, x_bins=None, x_ci='ci', scatter=True, fit_reg=True, ci=95, n_boot=1000, units=None, seed=None, order=1, logistic=False, lowess=False, robust=False, logx=False, x_partial=None, y_partial=None, truncate=True, dropna=True, x_jitter=None, y_jitter=None, label=None, color=None, marker='o', scatter_kws=None, line_kws=None, ax=None)#
绘制数据和线性回归模型拟合。
有许多用于估计回归模型的相互排斥的选项。有关更多信息,请参见 教程。
- 参数:
- x, y:字符串、序列或向量数组
输入变量。如果为字符串,则应与
data中的列名相对应。使用 pandas 对象时,轴将使用序列名称进行标记。- dataDataFrame
整齐(“长格式”)数据框,其中每列都是一个变量,每行都是一个观察结果。
- x_estimator将向量映射到标量的可调用函数,可选
将此函数应用于
x的每个唯一值并绘制所得估计值。当x是一个离散变量时,这很有用。如果提供了x_ci,则将对该估计值进行自举,并绘制置信区间。- x_bins整数或向量,可选
将
x变量划分为离散箱,然后估计中心趋势和置信区间。此箱装仅影响散点图的绘制方式;回归仍然适合原始数据。此参数被解释为均匀大小(不一定间距)箱的数量或箱中心的方位。使用此参数时,意味着x_estimator的默认值为numpy.mean。- x_ci“ci”、"sd"、[0, 100] 中的整数或 None,可选
在绘制离散
x值的中心趋势时使用的置信区间大小。如果为“ci”,则使用ci参数的值。如果为“sd”,则跳过自举并显示每个箱中观察值的标准差。- scatter布尔值,可选
如果为
True,则绘制包含基础观察结果(或x_estimator值)的散点图。- fit_reg布尔值,可选
如果为
True,则估计并绘制一个回归模型,该模型将x和y变量联系起来。- ci[0, 100] 中的整数或 None,可选
回归估计的置信区间大小。这将使用围绕回归线的半透明带绘制。置信区间使用自举估计;对于大型数据集,最好避免此计算,方法是将此参数设置为 None。
- n_boot整数,可选
用于估计
ci的自举重采样次数。默认值试图在时间和稳定性之间取得平衡;您可能希望为图的“最终”版本增加此值。- units
data中的变量名,可选 如果
x和y观察结果嵌套在采样单元内,则可以在这里指定这些单元。这将在计算置信区间时被考虑在内,方法是执行一个多级自举,该自举对单元和观察结果(在单元内)进行重采样。这不会影响回归的估计或绘制方式。- seed整数、numpy.random.Generator 或 numpy.random.RandomState,可选
用于可重复自举的种子或随机数生成器。
- order整数,可选
如果
order大于 1,则使用numpy.polyfit来估计多项式回归。- logistic布尔值,可选
如果为
True,则假设y是一个二元变量,并使用statsmodels来估计逻辑回归模型。请注意,这比线性回归计算量大得多,因此您可能希望减少自举重采样次数 (n_boot) 或将ci设置为 None。- lowess布尔值,可选
如果为
True,则使用statsmodels来估计非参数 lowess 模型(局部加权线性回归)。请注意,目前无法为这种类型的模型绘制置信区间。- robust布尔值,可选
如果为
True,则使用statsmodels来估计稳健回归。这将降低异常值的权重。请注意,这比标准线性回归计算量大得多,因此您可能希望减少自举重采样次数 (n_boot) 或将ci设置为 None。- logx布尔值,可选
如果为
True,则估计形式为 y ~ log(x) 的线性回归,但在输入空间中绘制散点图和回归模型。请注意,x必须为正值才能正常工作。- {x,y}_partial
data中的字符串或矩阵 混杂变量,在绘制之前从
x或y变量中回归出来。- truncate布尔值,可选
如果为
True,则回归线受数据限制。如果为False,则它延伸到x轴限制。- {x,y}_jitter浮点数,可选
在
x或y变量中添加此大小的均匀随机噪声。噪声是在拟合回归后添加到数据副本中的,只影响散点图的外观。当绘制取离散值的变量时,这可能会有所帮助。- label字符串
要应用于散点图或回归线的标签(如果
scatter为False),用于图例。- colormatplotlib 颜色
应用于所有绘图元素的颜色;将被
scatter_kws或line_kws中传递的颜色取代。- markermatplotlib 标记代码
用于散点图符号的标记。
- {scatter,line}_kws字典
要传递给
plt.scatter和plt.plot的其他关键字参数。- axmatplotlib Axes,可选
要绘制图形的 Axes 对象,否则使用当前 Axes。
- 返回值:
- axmatplotlib Axes
包含图形的 Axes 对象。
另请参见
注释
regplot()和lmplot()函数密切相关,但前者是轴级函数,而后者是图级函数,它结合了regplot()和FacetGrid。也很容易将
regplot()和JointGrid或PairGrid组合起来,通过jointplot()和pairplot()函数,尽管它们不直接接受regplot()的所有参数。示例
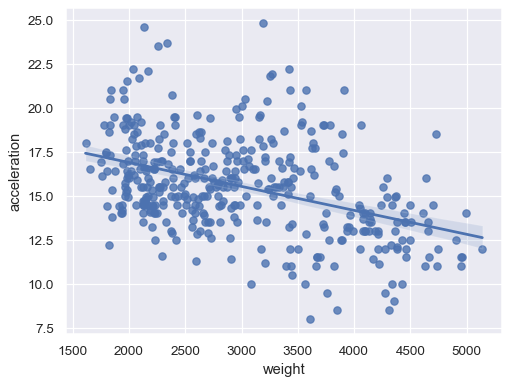
绘制 DataFrame 中两个变量之间的关系
sns.regplot(data=mpg, x="weight", y="acceleration")
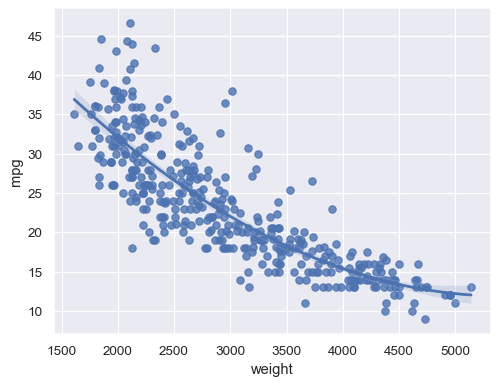
拟合更高阶的多项式回归以捕获非线性趋势
sns.regplot(data=mpg, x="weight", y="mpg", order=2)
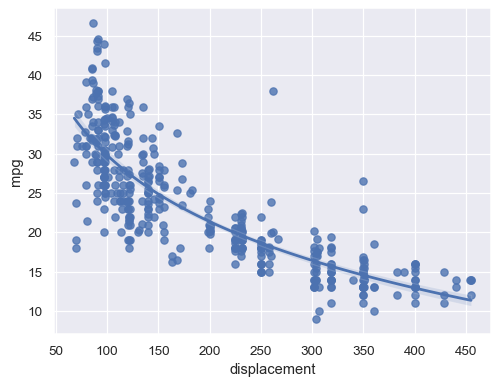
或者,拟合对数线性回归
sns.regplot(data=mpg, x="displacement", y="mpg", logx=True)
或使用局部加权(LOWESS)平滑器
sns.regplot(data=mpg, x="horsepower", y="mpg", lowess=True)
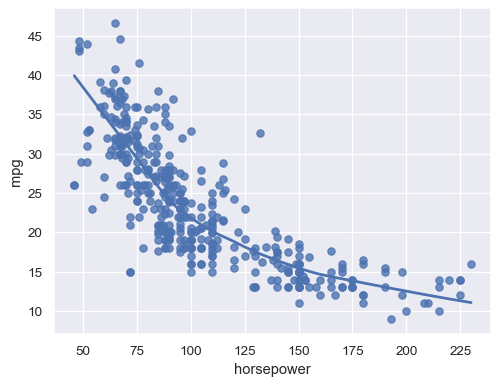
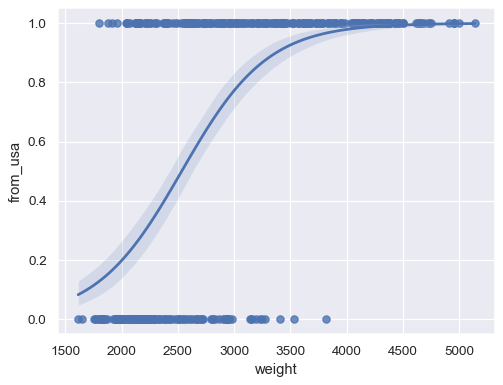
当响应变量为二元时,拟合逻辑回归
sns.regplot(x=mpg["weight"], y=mpg["origin"].eq("usa").rename("from_usa"), logistic=True)
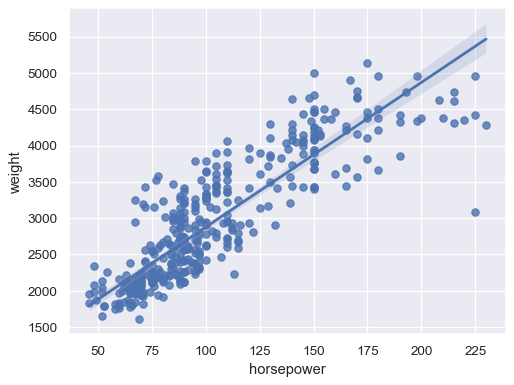
拟合稳健回归以降低异常值的影响
sns.regplot(data=mpg, x="horsepower", y="weight", robust=True)
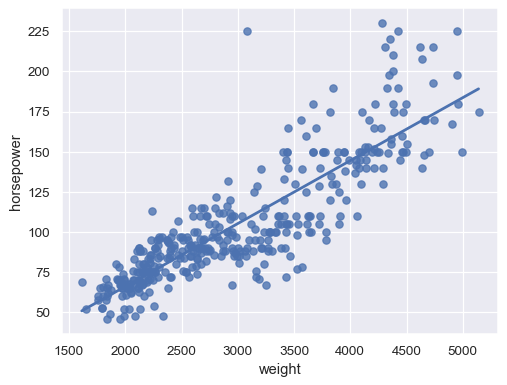
禁用置信区间以加快绘制速度
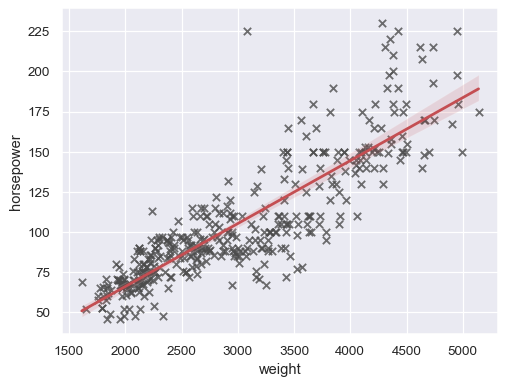
sns.regplot(data=mpg, x="weight", y="horsepower", ci=None)
当
x变量为离散时,抖动散点图sns.regplot(data=mpg, x="cylinders", y="weight", x_jitter=.15)
或汇总不同的
x值sns.regplot(data=mpg, x="cylinders", y="acceleration", x_estimator=np.mean, order=2)
对于连续的
x变量,进行分箱,然后汇总sns.regplot(data=mpg, x="weight", y="mpg", x_bins=np.arange(2000, 5500, 250), order=2)
自定义各种元素的外观
sns.regplot( data=mpg, x="weight", y="horsepower", ci=99, marker="x", color=".3", line_kws=dict(color="r"), )