seaborn.displot#
- seaborn.displot(data=None, *, x=None, y=None, hue=None, row=None, col=None, weights=None, kind='hist', rug=False, rug_kws=None, log_scale=None, legend=True, palette=None, hue_order=None, hue_norm=None, color=None, col_wrap=None, row_order=None, col_order=None, height=5, aspect=1, facet_kws=None, **kwargs)#
用于将分布图绘制到 FacetGrid 上的图级接口。
此函数提供了多种方法来可视化数据的单变量或双变量分布,包括通过语义映射定义的数据子集,以及跨多个子图的分面。
histplot()(使用kind="hist"; 默认为此)kdeplot()(使用kind="kde")ecdfplot()(使用kind="ecdf"; 仅限单变量)
此外,还可以将
rugplot()添加到任何类型的图中,以显示单个观测值。额外的关键字参数将传递给底层函数,因此您应该参考每个函数的文档以了解使用此接口绘制图形的完整选项集。
有关每种方法的相对优势和劣势的更深入讨论,请参阅 分布图教程。在 用户指南 中进一步解释了图级函数和轴级函数之间的区别。
- 参数::
- data
pandas.DataFrame,numpy.ndarray, 映射或序列 输入数据结构。可以分配给命名变量的长格式向量集合,或者将内部重塑的宽格式数据集。
- x, y向量或
data中的键 指定 x 轴和 y 轴上位置的变量。
- hue向量或
data中的键 映射以确定绘图元素颜色的语义变量。
- row, col向量或
data中的键 定义要绘制到不同分面上的子集的变量。
- weights向量或
data中的键 用于计算分布函数的观测权重。
- kind{“hist”, “kde”, “ecdf”}
用于可视化数据的方法。选择底层绘图函数并确定其他有效参数集。
- rugbool
如果为 True,则使用边缘刻度显示每个观测值(如
rugplot()中所做的那样)。- rug_kwsdict
用于控制毛毯图外观的参数。
- log_scalebool 或数字,或 bool 或数字对
将轴刻度设置为对数。单个值设置绘图中任何数值轴的数据轴。一对值独立设置每个轴。数值解释为所需基数(默认为 10)。当为
None或False时,seaborn 会转而使用现有轴刻度。- legendbool
如果为 False,则抑制语义变量的图例。
- palette字符串、列表、字典或
matplotlib.colors.Colormap 用于选择在映射
hue语义时使用的颜色的方法。字符串值传递给color_palette()。列表或字典值意味着类别映射,而颜色图对象意味着数值映射。- hue_order字符串向量
指定
hue语义的分类级别的处理和绘制顺序。- hue_norm元组或
matplotlib.colors.Normalize 可以是设置数据单位中归一化范围的一对值,也可以是将数据单位映射到[0, 1]区间的对象。使用意味着数值映射。
- color
matplotlib color 当不使用色调映射时,单个颜色规范。否则,绘图将尝试连接到 matplotlib 属性循环。
- col_wrap整数
以该宽度“包裹”列变量,以便列小平面跨越多行。与
row小平面不兼容。- {row,col}_order字符串向量
指定
row和/或col变量的级别在子图网格中出现的顺序。- height标量
每个小平面的高度(英寸)。另见:
aspect。- aspect标量
每个小平面的纵横比,因此
aspect * height给出每个小平面以英寸为单位的宽度。- facet_kws字典
传递给
FacetGrid的附加参数。- kwargs
其他关键字参数在相关轴级函数中记录
histplot()(使用kind="hist")kdeplot()(使用kind="kde")ecdfplot()(使用kind="ecdf")
- data
- 返回:
FacetGrid一个管理一个或多个子图的对象,这些子图对应于具有方便方法用于批量设置轴属性的条件数据子集。
另见
示例
有关每种绘图类型的可用选项范围的更多详细信息,请参阅轴级函数的 API 文档。
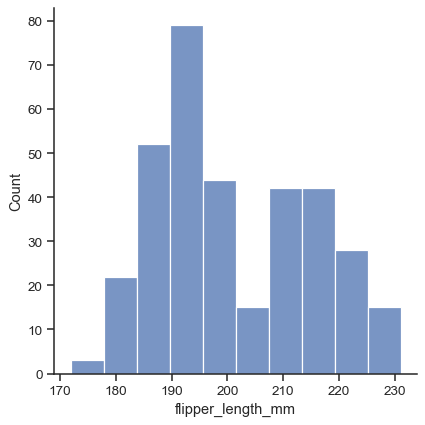
默认绘图类型是直方图
penguins = sns.load_dataset("penguins") sns.displot(data=penguins, x="flipper_length_mm")
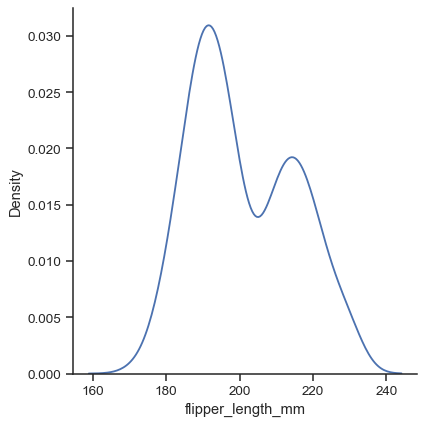
使用
kind参数选择不同的表示sns.displot(data=penguins, x="flipper_length_mm", kind="kde")
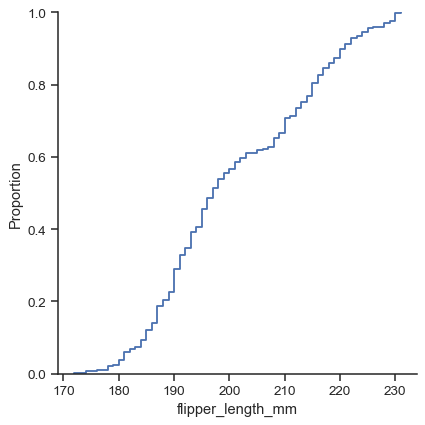
有三种主要绘图类型;除了直方图和核密度估计 (KDE) 之外,您还可以绘制经验累积分布函数 (ECDF)
sns.displot(data=penguins, x="flipper_length_mm", kind="ecdf")
在直方图模式下,也可以添加 KDE 曲线
sns.displot(data=penguins, x="flipper_length_mm", kde=True)
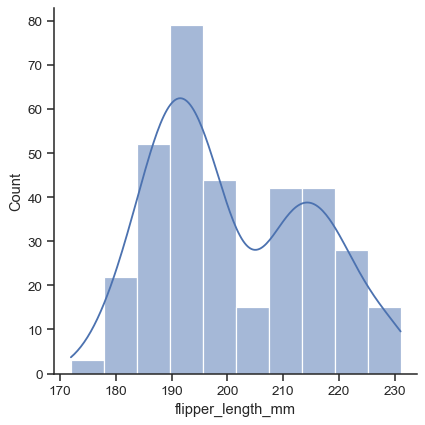
要绘制双变量图,请同时分配
x和ysns.displot(data=penguins, x="flipper_length_mm", y="bill_length_mm")
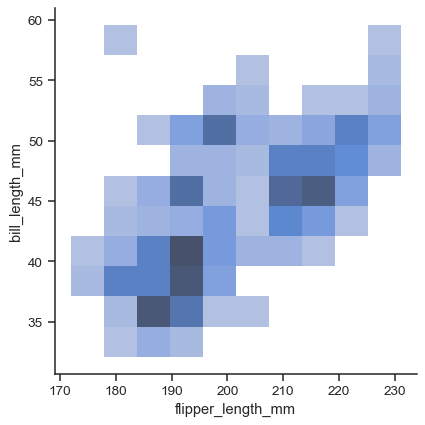
目前,双变量图仅适用于直方图和 KDE
sns.displot(data=penguins, x="flipper_length_mm", y="bill_length_mm", kind="kde")
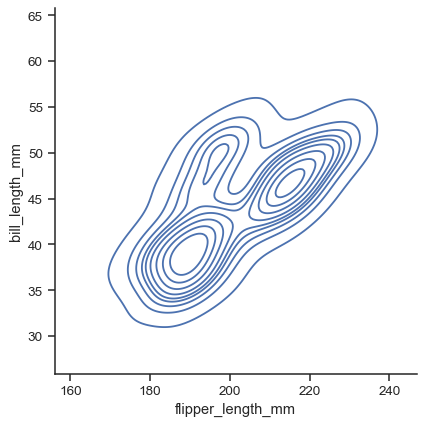
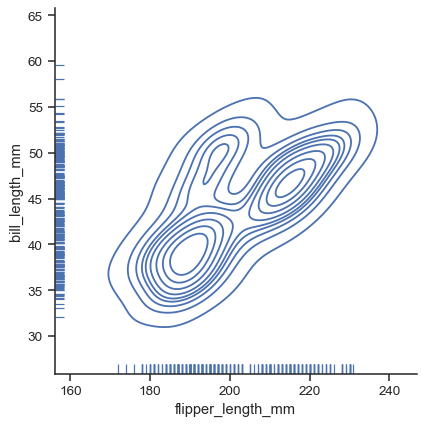
对于每种绘图类型,您还可以使用边缘“地毯”显示单个观察值
g = sns.displot(data=penguins, x="flipper_length_mm", y="bill_length_mm", kind="kde", rug=True)
每种绘图类型都可以使用
hue映射为数据子集单独绘制sns.displot(data=penguins, x="flipper_length_mm", hue="species", kind="kde")
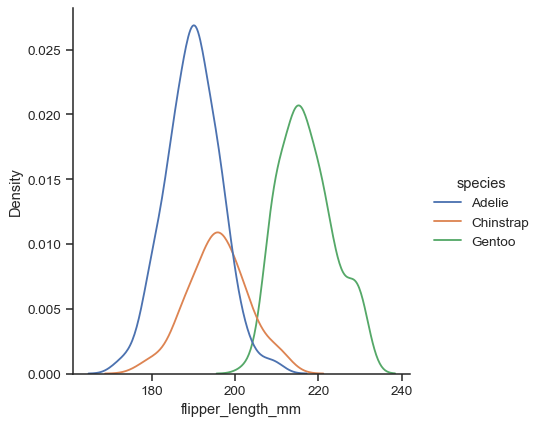
附加关键字参数传递给相应的底层绘图函数,允许进一步自定义
sns.displot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")
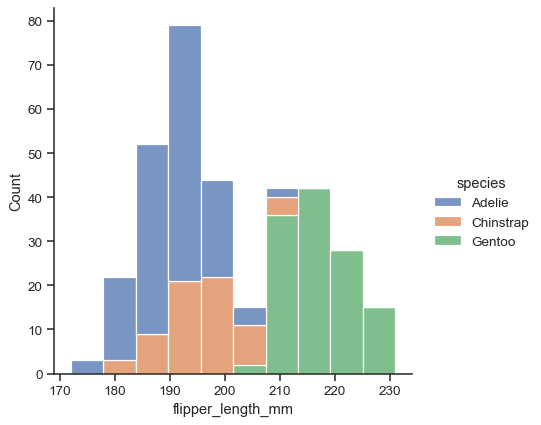
该图形使用
FacetGrid构建,这意味着您还可以显示不同子图上的子集,或“小平面”sns.displot(data=penguins, x="flipper_length_mm", hue="species", col="sex", kind="kde")
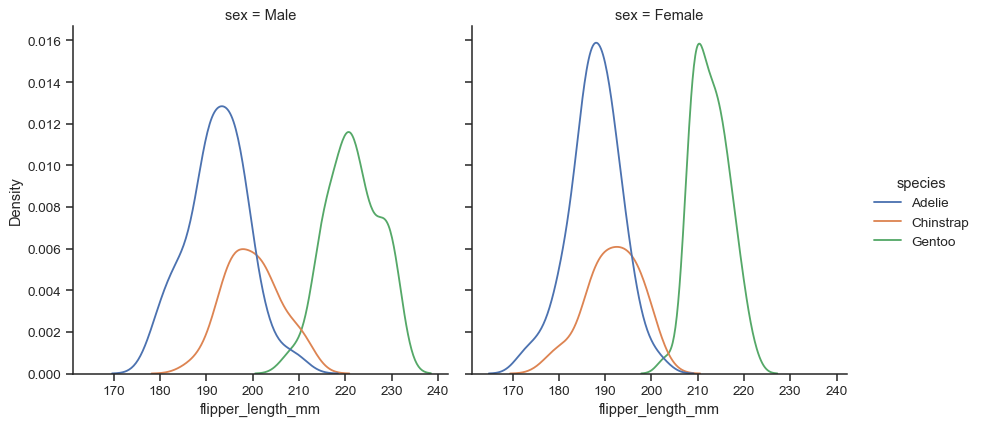
因为该图形使用
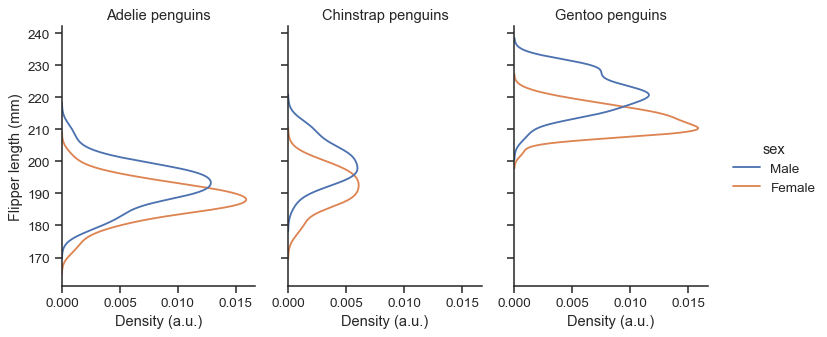
FacetGrid绘制,所以您可以使用height和aspect参数控制其大小和形状sns.displot( data=penguins, y="flipper_length_mm", hue="sex", col="species", kind="ecdf", height=4, aspect=.7, )
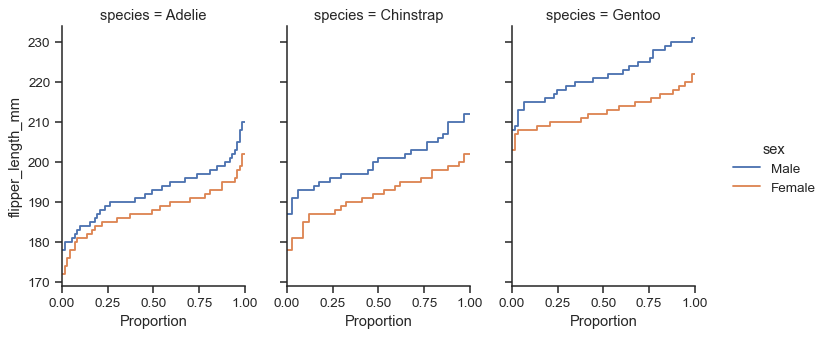
该函数返回带有绘图的
FacetGrid对象,您可以使用此对象上的方法进一步对其进行自定义g = sns.displot( data=penguins, y="flipper_length_mm", hue="sex", col="species", kind="kde", height=4, aspect=.7, ) g.set_axis_labels("Density (a.u.)", "Flipper length (mm)") g.set_titles("{col_name} penguins")