seaborn.catplot#
- seaborn.catplot(data=None, *, x=None, y=None, hue=None, row=None, col=None, kind='strip', estimator='mean', errorbar=('ci', 95), n_boot=1000, seed=None, units=None, weights=None, order=None, hue_order=None, row_order=None, col_order=None, col_wrap=None, height=5, aspect=1, log_scale=None, native_scale=False, formatter=None, orient=None, color=None, palette=None, hue_norm=None, legend='auto', legend_out=True, sharex=True, sharey=True, margin_titles=False, facet_kws=None, ci=<deprecated>, **kwargs)#
在 FacetGrid 上绘制分类图的图级接口。
此函数提供对几个轴级函数的访问,这些函数使用几种视觉表示中的一个来显示数值变量和一个或多个分类变量之间的关系。
kind参数选择要使用的基础轴级函数。分类散点图
stripplot()(使用kind="strip"; 默认为此)swarmplot()(使用kind="swarm")
分类分布图
boxplot()(使用kind="box")violinplot()(使用kind="violin")boxenplot()(使用kind="boxen")
分类估计图
pointplot()(使用kind="point")barplot()(使用kind="bar")countplot()(使用kind="count")
额外的关键字参数将传递给底层函数,因此您应该参考每个函数的文档以查看特定于类型的选项。
有关更多信息,请参见 教程。
注意
默认情况下,此函数将一个变量视为分类变量,并在相关轴上以序数位置(0、1、… n)绘制数据。 从 0.13.0 版本开始,可以通过设置
native_scale=True来禁用此功能。绘制完成后,将返回带有图的
FacetGrid,并且可以直接使用它来调整支持的绘图细节或添加其他图层。- 参数::
- dataDataFrame、Series、dict、array 或 array 列表
用于绘图的数据集。 如果
x和y缺失,则将其解释为宽格式。 否则,预计其为长格式。- x、y、hue数据中的变量名称或向量数据
用于绘制长格式数据的输入。 请参见示例了解解释。
- row、col数据中的变量名称或向量数据
将确定网格分面的分类变量。
- kindstr
要绘制的绘图类型,对应于分类轴级绘图函数的名称。 选项包括:“strip”、“swarm”、“box”、“violin”、“boxen”、“point”、“bar” 或 “count”。
- estimator将向量映射到标量的字符串或可调用对象
在每个分类箱内估计的统计函数。
- errorbar字符串、(字符串、数字)元组、可调用对象或 None
误差线方法的名称(“ci”、“pi”、“se” 或 “sd”),或包含方法名称和级别参数的元组,或将向量映射到 (min, max) 区间的函数,或 None 来隐藏误差线。 有关更多信息,请参见 误差线教程。
版本 v0.12.0 中的新增功能。
- n_bootint
用于计算置信区间的自举样本数量。
- seedint、
numpy.random.Generator或numpy.random.RandomState 用于可重复自举的种子或随机数生成器。
- units数据中的变量名称或向量数据
采样单元的标识符;误差线函数使用它来执行多级自举并考虑重复测量。
- weights数据中的变量名称或向量数据
用于计算加权统计数据的数据值或列。 请注意,使用权重可能会限制其他统计选项。
版本 v0.13.1 中的新增功能。
- order、hue_order字符串列表
绘制分类级别的顺序;否则,级别将从数据对象推断。
- row_order、col_order字符串列表
组织网格行和/或列的顺序;否则,顺序将从数据对象推断。
- col_wrapint
以此宽度“包装”列变量,以便列分面跨越多行。 与
row分面不兼容。- height标量
每个面的高度(以英寸为单位)。另请参见:
aspect。- aspect标量
每个面的纵横比,因此
aspect * height给出每个面的宽度(以英寸为单位)。- native_scale布尔值
当为 True 时,分类轴上的数值或日期时间值将保持其原始缩放比例,而不是转换为固定索引。
新版本 v0.13.0 中添加。
- formatter可调用对象
将分类数据转换为字符串的函数。影响分组和刻度标签。
新版本 v0.13.0 中添加。
- orient“v” | “h” | “x” | “y”
图表的方位(垂直或水平)。这通常根据输入变量的类型推断出来,但可用于解决当
x和y都是数值型或绘制宽格式数据时出现的歧义。版本 v0.13.0 中变更:添加了 'x'/'y' 作为选项,等效于 'v'/'h'。
- colormatplotlib 颜色
用于图中元素的单一颜色。
- palette调色板名称、列表或字典
用于
hue变量的不同级别的颜色。应该可以被color_palette()解释,或者是一个将色调级别映射到 matplotlib 颜色的字典。- hue_norm元组或
matplotlib.colors.Normalize对象 当
hue变量是数值型时,应用于hue变量的颜色图的数据单位中的归一化。如果hue是分类型,则不相关。版本 v0.12.0 中的新增功能。
- legend“auto”, “brief”, “full”, or False
如何绘制图例。如果为 “brief”,则数值型
hue和size变量将用均匀间隔值的样本表示。如果为 “full”,则每个组将在图例中获得一个条目。如果为 “auto”,则根据级别的数量选择简要或完整的表示形式。如果为False,则不会添加图例数据,也不会绘制图例。新版本 v0.13.0 中添加。
- legend_out布尔值
如果为
True,则图形大小将被扩展,并且图例将绘制在图的中心右侧之外。- share{x,y}布尔值、'col' 或 'row'(可选)
如果为 true,则各个面将跨列共享 y 轴,或跨行共享 x 轴。
- margin_titles布尔值
如果为
True,则行变量的标题将绘制在最后一列的右侧。此选项是实验性的,可能并非在所有情况下都有效。- facet_kws字典
传递给
FacetGrid的其他关键字参数的字典。- kwargs键值对
其他关键字参数将传递给底层绘图函数。
- 返回:
示例
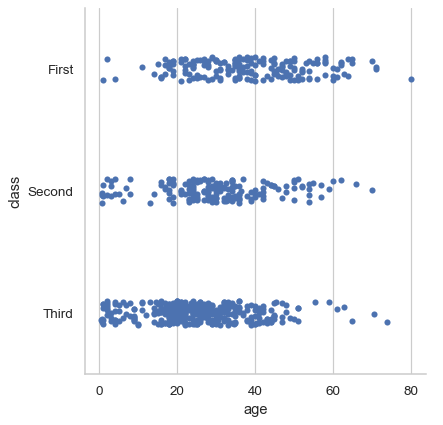
默认情况下,可视化表示将是抖动的条形图
df = sns.load_dataset("titanic") sns.catplot(data=df, x="age", y="class")
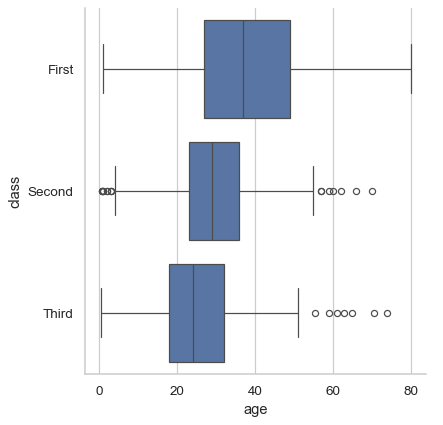
使用
kind选择不同的表示形式sns.catplot(data=df, x="age", y="class", kind="box")
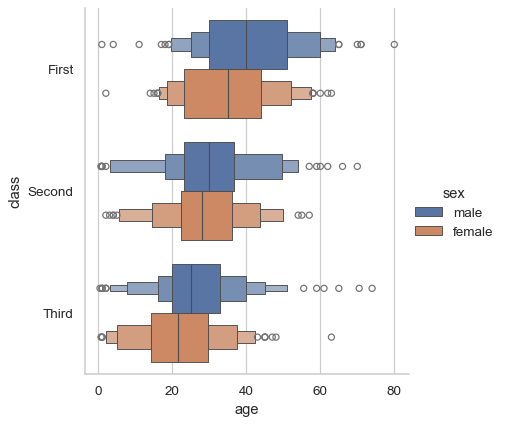
一个优点是图例会自动放置在图之外
sns.catplot(data=df, x="age", y="class", hue="sex", kind="boxen")
其他关键字参数将传递给底层 seaborn 函数
sns.catplot( data=df, x="age", y="class", hue="sex", kind="violin", bw_adjust=.5, cut=0, split=True, )
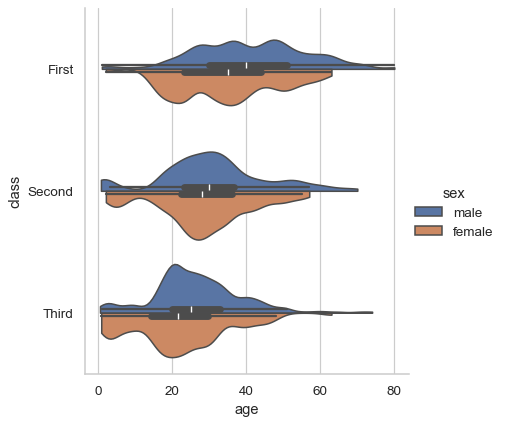
将变量分配给
col或row将自动创建子图。使用height和aspect参数控制图形大小sns.catplot( data=df, x="class", y="survived", col="sex", kind="bar", height=4, aspect=.6, )
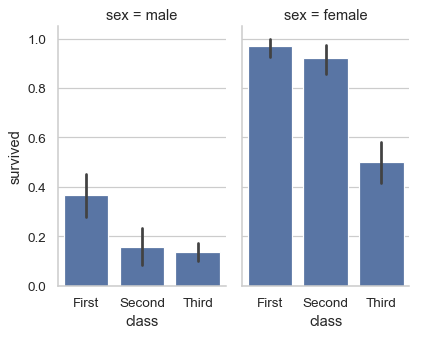
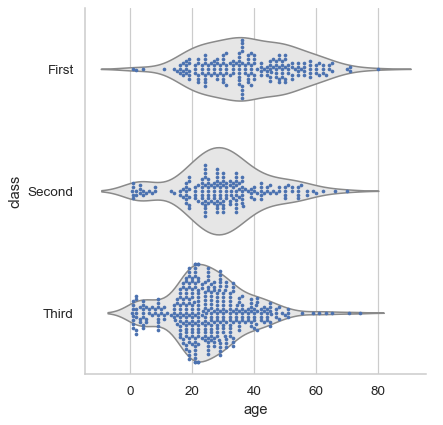
对于单子图图形,轻松叠加不同的表示形式
sns.catplot(data=df, x="age", y="class", kind="violin", color=".9", inner=None) sns.swarmplot(data=df, x="age", y="class", size=3)
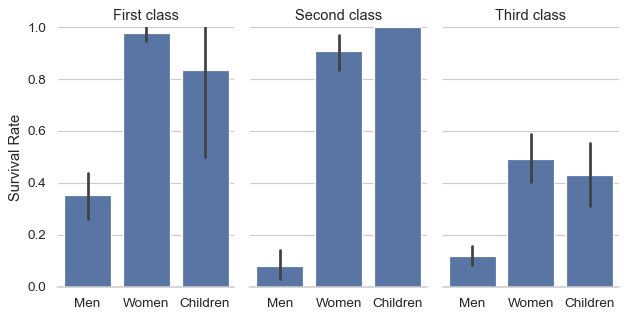
使用返回的
FacetGrid上的方法来调整演示g = sns.catplot( data=df, x="who", y="survived", col="class", kind="bar", height=4, aspect=.6, ) g.set_axis_labels("", "Survival Rate") g.set_xticklabels(["Men", "Women", "Children"]) g.set_titles("{col_name} {col_var}") g.set(ylim=(0, 1)) g.despine(left=True)