seaborn.pointplot#
- seaborn.pointplot(data=None, *, x=None, y=None, hue=None, order=None, hue_order=None, estimator='mean', errorbar=('ci', 95), n_boot=1000, seed=None, units=None, weights=None, color=None, palette=None, hue_norm=None, markers=<default>, linestyles=<default>, dodge=False, log_scale=None, native_scale=False, orient=None, capsize=0, formatter=None, legend='auto', err_kws=None, ci=<deprecated>, errwidth=<deprecated>, join=<deprecated>, scale=<deprecated>, ax=None, **kwargs)#
使用带有标记的线显示点估计值和误差。
点图通过点的定位表示对数值变量的集中趋势的估计,并使用误差条提供该估计值周围的不确定性的指示。
点图比条形图更有用,因为它们可以集中关注一个或多个分类变量的不同水平之间的比较。它们在显示交互方面特别擅长:一个分类变量的水平之间的关系如何随第二个分类变量的水平而变化。连接来自相同
hue级别中每个点的线允许通过斜率的差异来判断交互,这比比较几组点或条形图的高度更容易。有关更多信息,请参阅教程。
注意
默认情况下,此函数将一个变量视为分类变量,并在相关轴上以序数位置 (0, 1, … n) 绘制数据。从 0.13.0 版本开始,可以通过设置
native_scale=True来禁用此功能。- 参数:
- dataDataFrame、Series、dict、array 或 array 列表
用于绘图的数据集。如果
x和y缺失,则将其解释为宽格式。否则,预期它是长格式。- x、y、hue
data中的变量名称或矢量数据 用于绘制长格式数据的输入。有关解释,请参阅示例。
- order、hue_order字符串列表
绘制分类级别的顺序;否则,级别将从数据对象中推断出来。
- estimator将向量映射到标量的字符串或可调用对象
用于估计每个分类箱内的统计函数。
- errorbar字符串、(字符串、数字) 元组、可调用对象或 None
误差条方法的名称(“ci”、“pi”、“se”或“sd”之一),或者包含方法名称和级别参数的元组,或者一个将向量映射到 (最小值、最大值) 区间的函数,或者 None 用于隐藏误差条。有关更多信息,请参阅误差条教程。
v0.12.0 版新增。
- n_bootint
用于计算置信区间的自举样本数。
- seedint、
numpy.random.Generator或numpy.random.RandomState 用于可重复自举的种子或随机数生成器。
- units
data中的变量名称或矢量数据 采样单位的标识符;用于误差条函数以执行多级自举并考虑重复测量
- weights
data中的变量名称或矢量数据 用于计算加权统计量的数据值或列。请注意,使用权重可能会限制其他统计选项。
v0.13.1 版新增。
- colormatplotlib 颜色
用于图中元素的单一颜色。
- palette调色板名称、列表或 dict
用于
hue变量的不同级别的颜色。应该是可以通过color_palette()解释的内容,或者一个将色调级别映射到 matplotlib 颜色的字典。- markers字符串或字符串列表
用于每个
hue级别的标记。- linestyles字符串或字符串列表
用于每个
hue级别的线型。- dodge布尔值或浮点数
沿分类轴将每个
hue变量级别的点分开的程度。设置为True将应用一个小的默认值。- log_scale布尔值或数字,或布尔值或数字对
将轴刻度设置为对数。单个值将设置图中任何数值轴的数据轴。一对值将独立设置每个轴。数值将解释为所需的底数 (默认值为 10)。当为
None或False时,seaborn 将使用现有 Axes 刻度。v0.13.0 版新增。
- native_scale布尔值
当为 True 时,分类轴上的数值或日期时间值将保持其原始刻度,而不是转换为固定索引。
v0.13.0 版新增。
- orient“v” | “h” | “x” | “y”
图表的朝向(垂直或水平)。这通常根据输入变量的类型推断得出,但它可用于解决当
x和y都是数值型或绘制宽格式数据时出现的歧义。在 v0.13.0 版本中变更: 添加了 'x'/'y' 作为选项,等效于 'v'/'h'。
- capsize浮点数
误差线“帽”的宽度,相对于条形间距。
- formatter可调用对象
用于将分类数据转换为字符串的函数。影响分组和刻度标签。
v0.13.0 版新增。
- legend“auto”, “brief”, “full”, 或 False
如何绘制图例。如果为“brief”,则数值型
hue和size变量将用均匀间隔值的样本表示。如果为“full”,则每个组将在图例中获得一个条目。如果为“auto”,则根据级别的数量选择简要或完整表示。如果为False,则不会添加图例数据,也不会绘制图例。v0.13.0 版新增。
- err_kws字典
matplotlib.lines.Line2D的参数,用于误差线绘图对象。v0.13.0 版新增。
- ci浮点数
要显示的置信区间的置信水平,范围在 [0, 100] 之间。
自 v0.12.0 版本起已弃用: 使用
errorbar=("ci", ...)。- errwidth浮点数
误差线(以及帽)的厚度,以点为单位。
自 v0.13.0 版本起已弃用: 使用
err_kws={'linewidth': ...}。- join布尔值
如果为
True,则用线连接点估计。自 v0.13.0 版本起已弃用: 设置
linestyle="none"以移除点之间的线。- scale浮点数
绘图元素的比例因子。
自 v0.13.0 版本起已弃用: 使用
matplotlib.lines.Line2D参数控制元素大小。- axmatplotlib Axes
要在其上绘制图形的 Axes 对象,否则使用当前 Axes。
- kwargs键值映射
其他参数将传递给
matplotlib.lines.Line2D。v0.13.0 版新增。
- 返回值:
- axmatplotlib Axes
返回绘制了图形的 Axes 对象。
备注
务必牢记,点图仅显示均值(或其他估计量)值,但在许多情况下,显示分类变量每个级别值的分布可能更有信息量。在这种情况下,其他方法(如箱线图或小提琴图)可能更合适。
示例
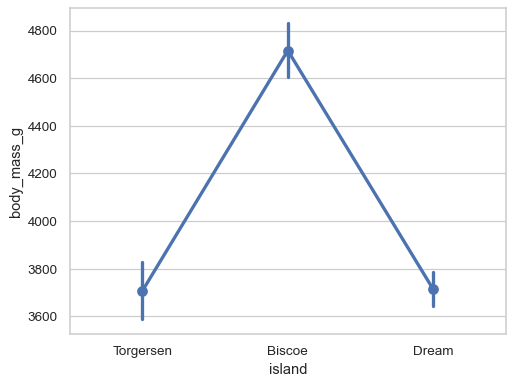
按分类变量分组并绘制汇总值,以及置信区间
sns.pointplot(data=penguins, x="island", y="body_mass_g")
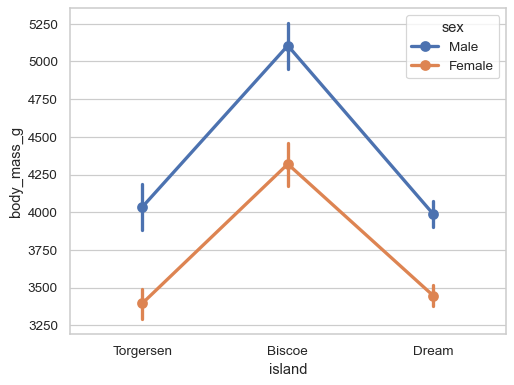
添加第二层分组并使用颜色区分
sns.pointplot(data=penguins, x="island", y="body_mass_g", hue="sex")
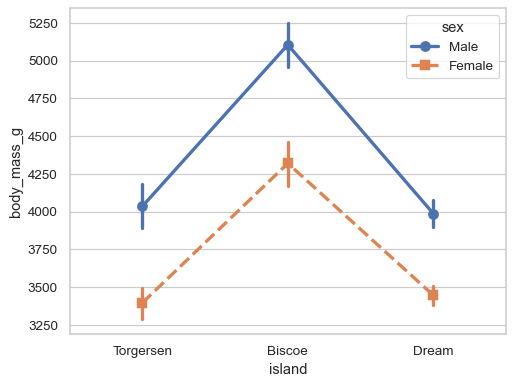
使用标记和线型冗余地编码
hue变量,以提高可访问性sns.pointplot( data=penguins, x="island", y="body_mass_g", hue="sex", markers=["o", "s"], linestyles=["-", "--"], )
使用误差线表示每个分布的标准差
sns.pointplot(data=penguins, x="island", y="body_mass_g", errorbar="sd")
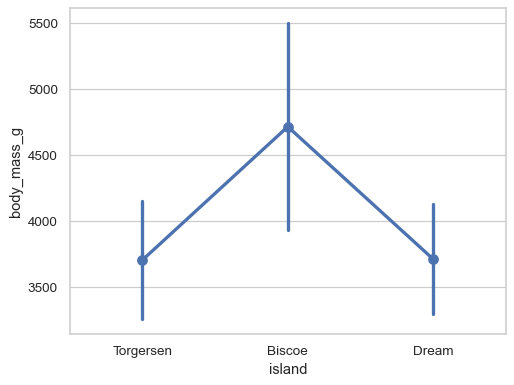
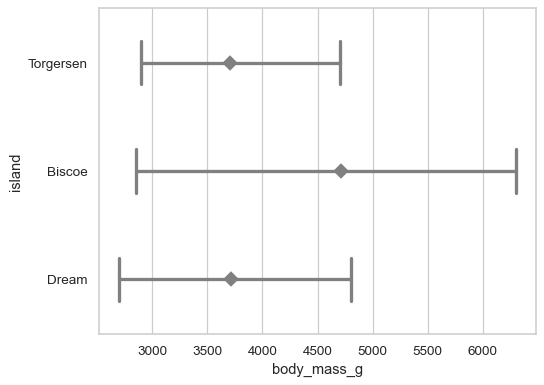
自定义图形的外观
sns.pointplot( data=penguins, x="body_mass_g", y="island", errorbar=("pi", 100), capsize=.4, color=".5", linestyle="none", marker="D", )
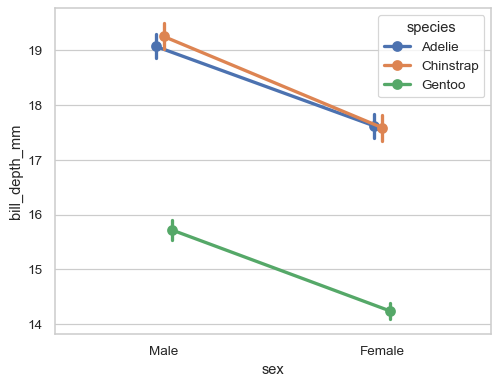
沿分类轴“躲避”绘图对象以减少过度绘制
sns.pointplot(data=penguins, x="sex", y="bill_depth_mm", hue="species", dodge=True)
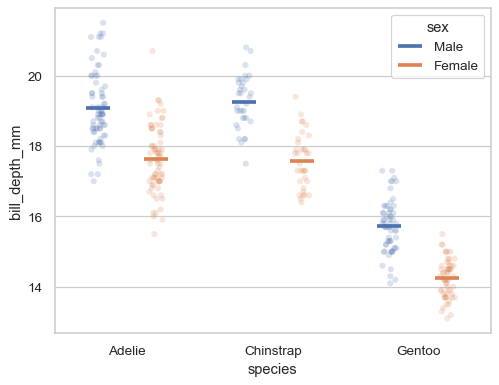
按特定量躲避,相对于分配给每个级别的宽度
sns.stripplot( data=penguins, x="species", y="bill_depth_mm", hue="sex", dodge=True, alpha=.2, legend=False, ) sns.pointplot( data=penguins, x="species", y="bill_depth_mm", hue="sex", dodge=.4, linestyle="none", errorbar=None, marker="_", markersize=20, markeredgewidth=3, )
当变量未显式分配且数据集为二维时,图形将汇总每列
flights_wide = flights.pivot(index="year", columns="month", values="passengers") sns.pointplot(flights_wide)
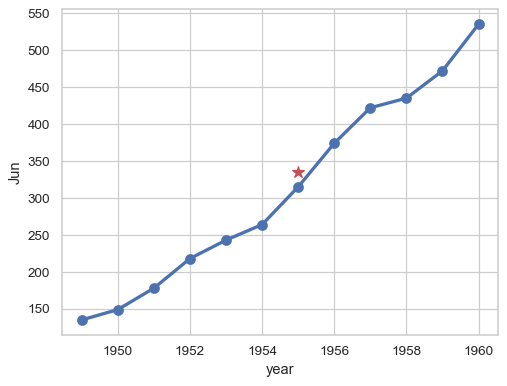
对于一维数据,将绘制每个值(相对于其键或索引,如果可用)
sns.pointplot(flights_wide["Jun"])
控制分类变量在刻度标签中显示的格式
sns.pointplot(flights_wide["Jun"], formatter=lambda x: f"'{x % 1900}")
或保留分组变量的本机刻度
ax = sns.pointplot(flights_wide["Jun"], native_scale=True) ax.plot(1955, 335, marker="*", color="r", markersize=10)