seaborn.objects.Est#
- class seaborn.objects.Est(func='mean', errorbar=('ci', 95), n_boot=1000, seed=None)#
计算点估计和误差条区间。
有关各种
errorbar选项的更多信息,请参阅 误差条教程。其他变量
weight: 当传递给使用此统计信息的层时,将计算加权估计。请注意,目前,权重的使用将函数和误差条方法的选择限制为分别为
"mean"和"ci"。
- 参数:
- funcstr 或 callable
numpy.ndarray方法的名称或向量 -> 标量函数。- errorbarstr、(str, float) 元组或 callable
误差条方法的名称(“ci”、“pi”、“se”或“sd”之一),或包含方法名称和级别参数的元组,或将向量映射到 (min, max) 区间的函数。
- n_bootint
为“ci”误差条绘制的引导样本数量。
- seedint
用于绘制引导样本的 PRNG 种子。
示例
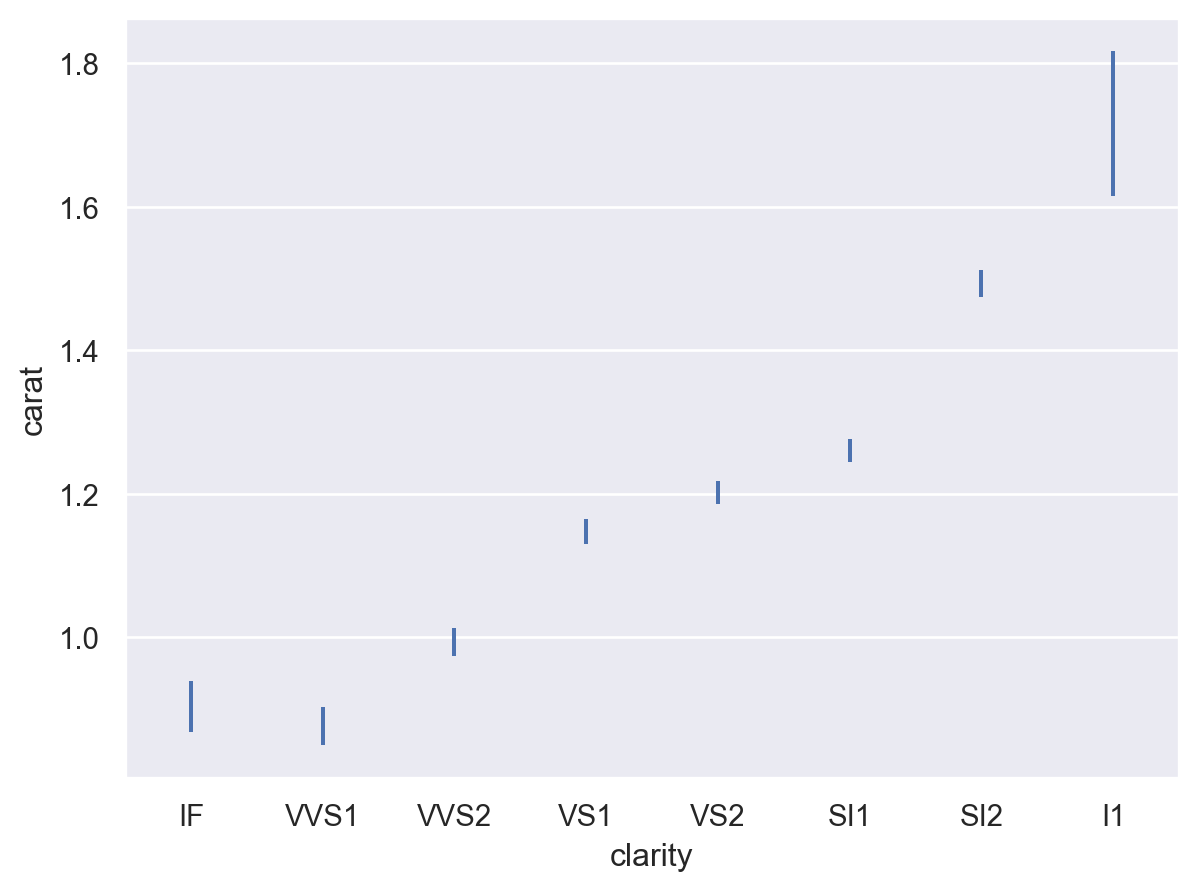
默认行为是计算平均值和 95% 置信区间(使用引导方法)
p = so.Plot(diamonds, "clarity", "carat") p.add(so.Range(), so.Est())
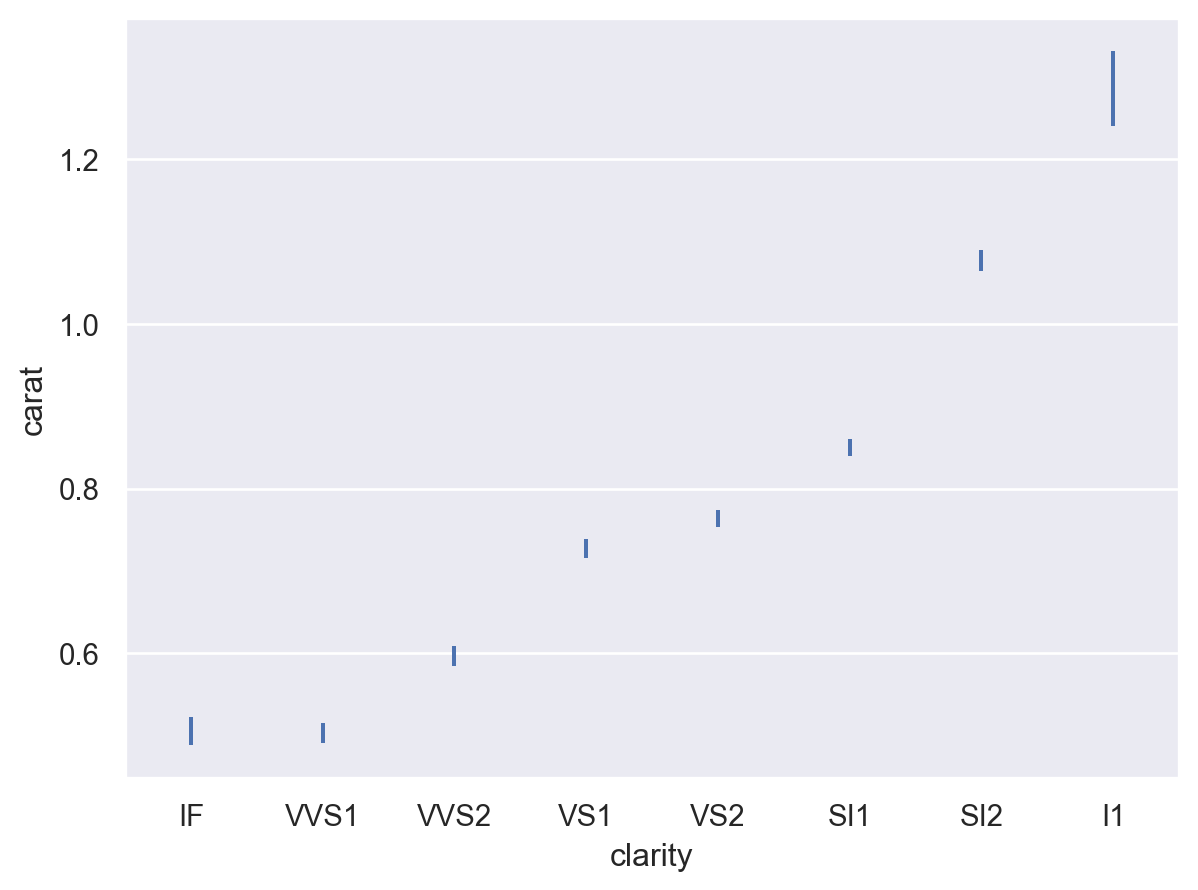
如果它们是 pandas 方法,则可以通过名称选择其他估计器
p.add(so.Range(), so.Est("median"))
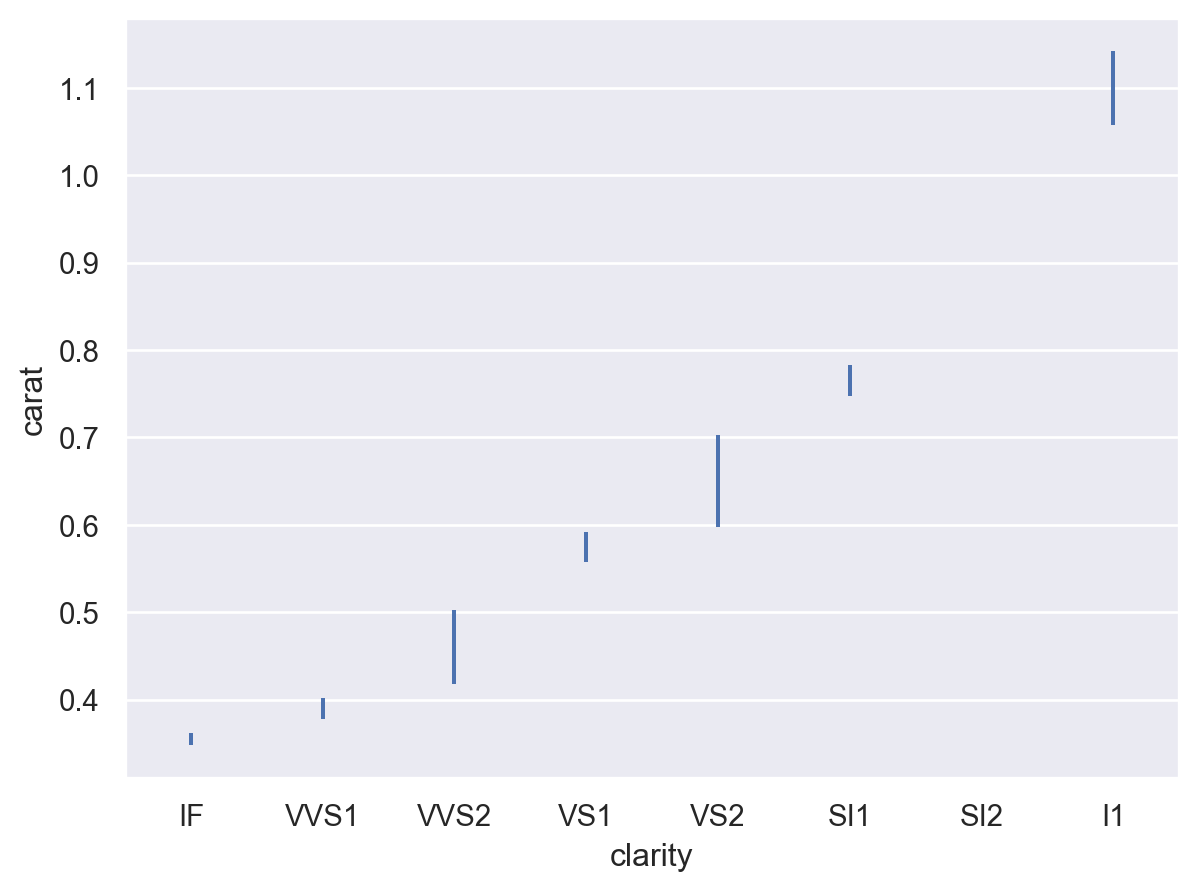
计算误差条区间的选项有多种,例如(缩放的)标准误差
p.add(so.Range(), so.Est(errorbar="se"))
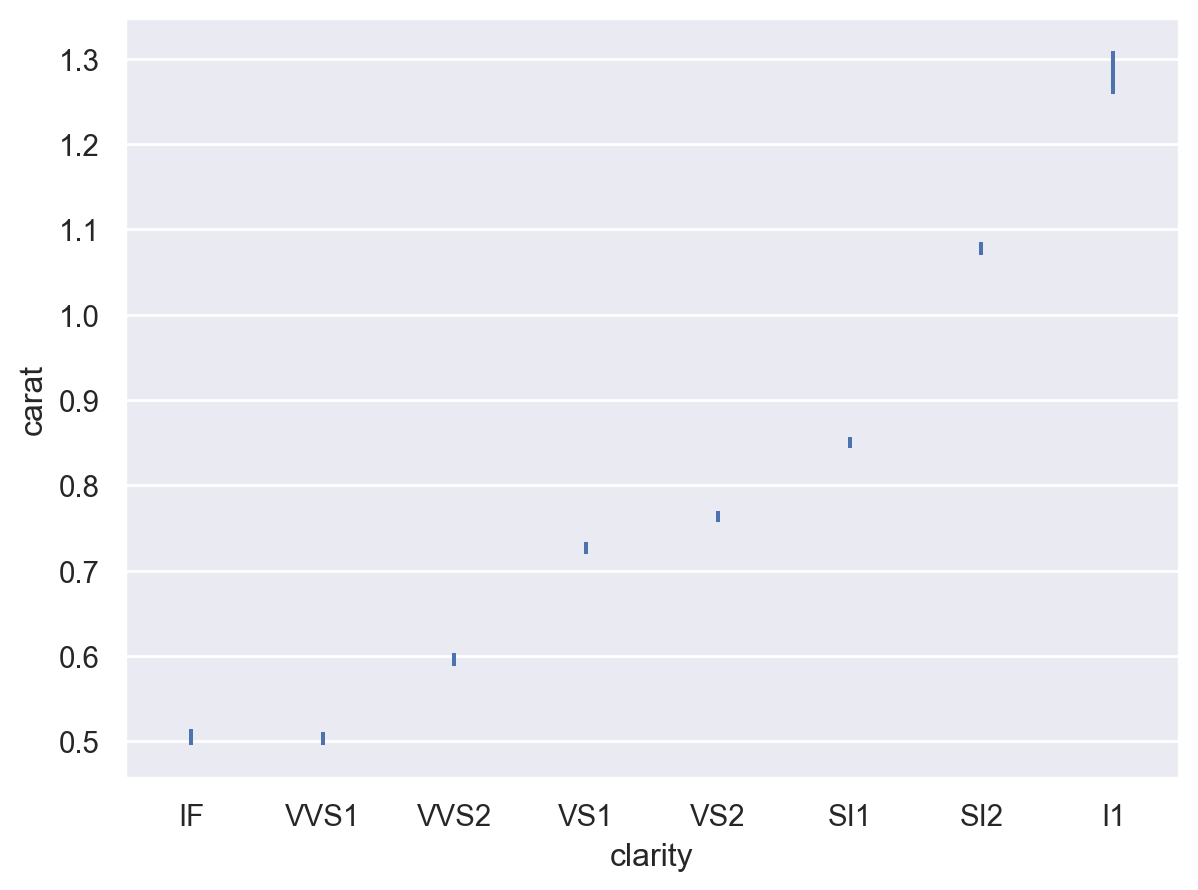
误差条还可以使用(缩放的)标准差表示围绕估计值的分布范围
p.add(so.Range(), so.Est(errorbar="sd"))
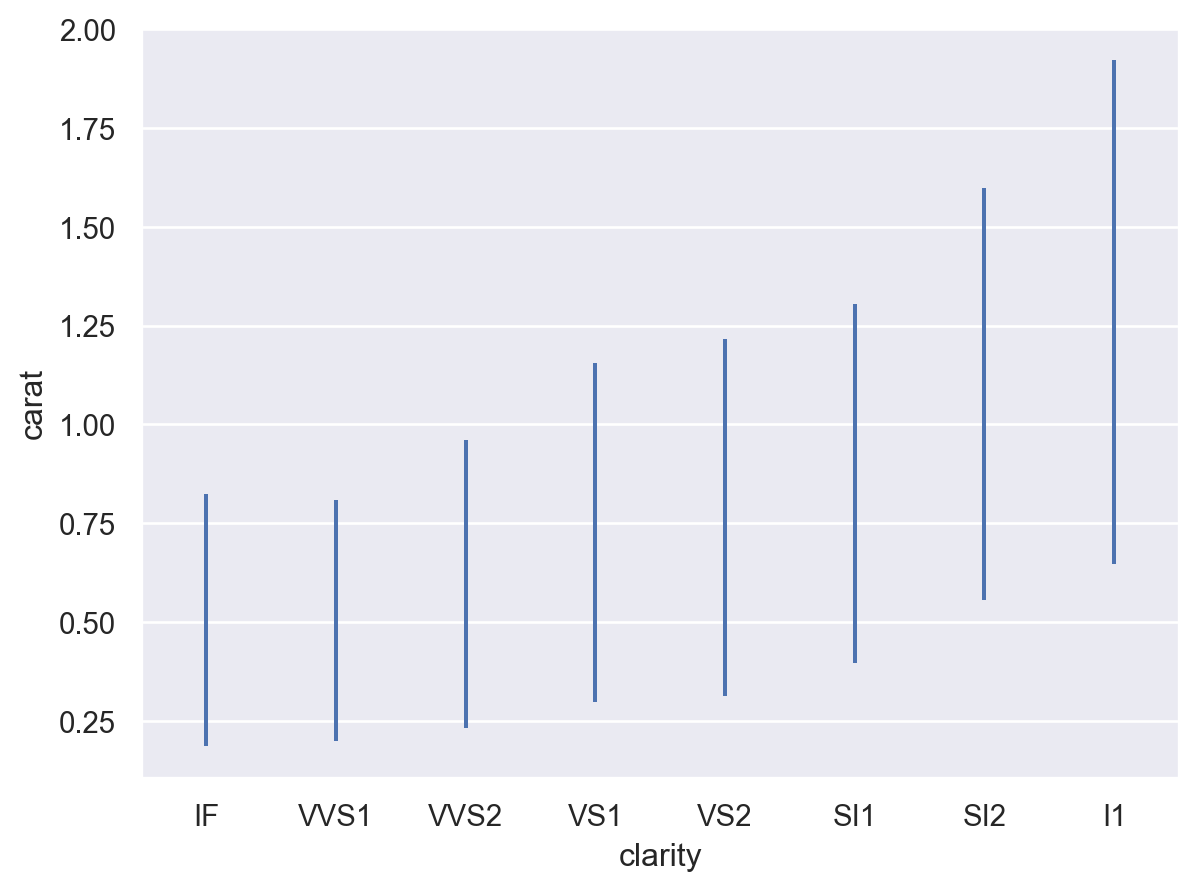
由于置信区间是使用引导方法计算的,因此会存在少量随机性。通过增加引导迭代次数来减少随机变异性(尽管这会比较慢),或者通过对随机数生成器进行播种来消除随机性
p.add(so.Range(), so.Est(seed=0))
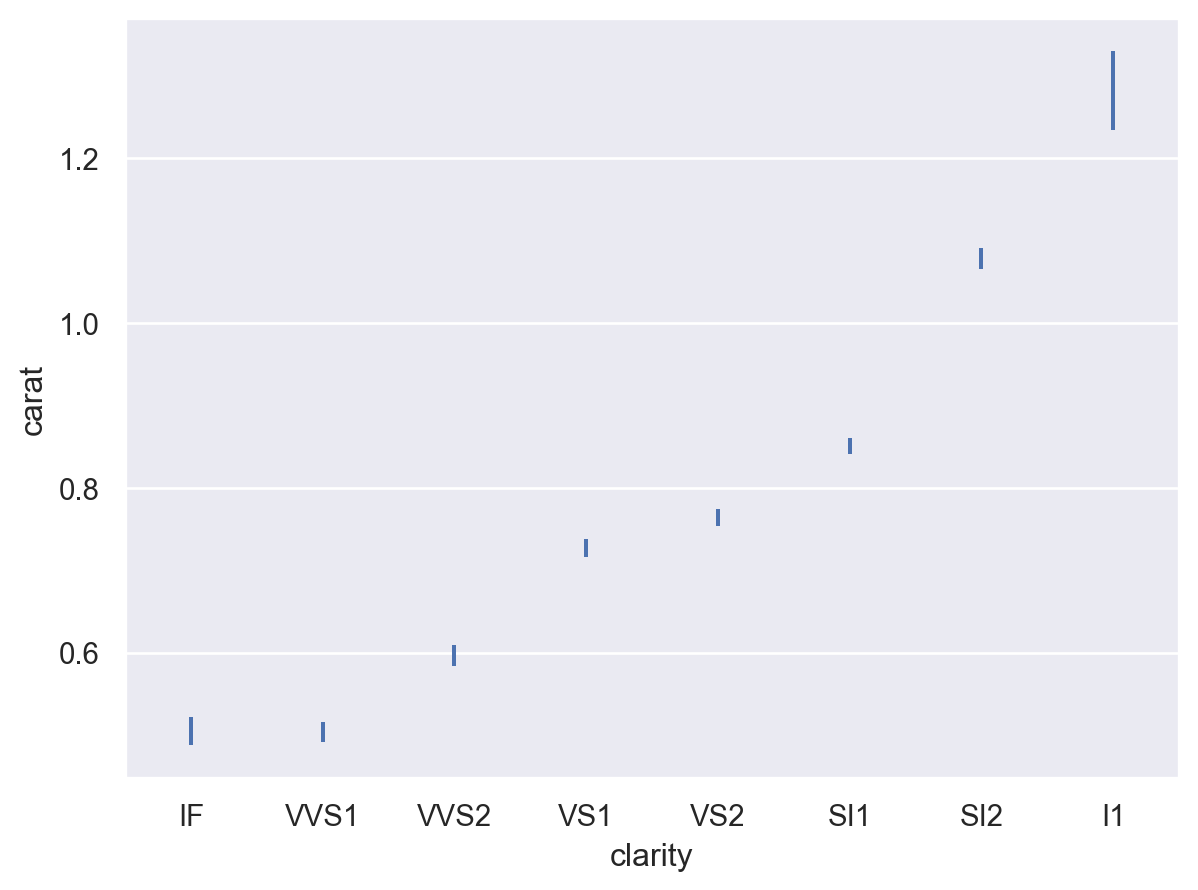
要计算加权估计(和置信区间),请在使用该统计信息的层中分配一个
weight变量p.add(so.Range(), so.Est(), weight="price")