seaborn.histplot#
- seaborn.histplot(data=None, *, x=None, y=None, hue=None, weights=None, stat='count', bins='auto', binwidth=None, binrange=None, discrete=None, cumulative=False, common_bins=True, common_norm=True, multiple='layer', element='bars', fill=True, shrink=1, kde=False, kde_kws=None, line_kws=None, thresh=0, pthresh=None, pmax=None, cbar=False, cbar_ax=None, cbar_kws=None, palette=None, hue_order=None, hue_norm=None, color=None, log_scale=None, legend=True, ax=None, **kwargs)#
绘制单变量或双变量直方图以显示数据集的分布。
直方图是一种经典的可视化工具,它通过计算落在离散箱中的观察次数来表示一个或多个变量的分布。
此函数可以对每个箱中计算的统计量进行归一化,以估计频率、密度或概率质量,并且可以添加使用内核密度估计获得的平滑曲线,类似于
kdeplot().更多信息请参阅 用户指南.
- 参数:
- data
pandas.DataFrame,numpy.ndarray, 映射,或序列 输入数据结构。可以分配给命名变量的长格式向量集合,或者将被内部重新塑形的宽格式数据集。
- x, y向量或
data中的键 指定 x 和 y 轴上位置的变量。
- hue向量或
data中的键 语义变量,用于映射以确定绘图元素的颜色。
- weights向量或
data中的键 如果提供,则通过这些因子对对应数据点对每个箱中计数的贡献进行加权。
- statstr
在每个箱中计算的聚合统计量。
count: 显示每个箱中的观察次数frequency: 显示观察次数除以箱宽probability或proportion: 归一化,使条形高度之和为 1percent: 归一化,使条形高度之和为 100density: 归一化,使直方图的总面积等于 1
- binsstr, number, vector, 或一对这样的值
可以是参考规则的名称、箱数或箱中断点的通用箱参数。传递给
numpy.histogram_bin_edges().- binwidth数字或数字对
每个箱体的宽度,覆盖
bins但可以与binrange一起使用。- binrange数字对或数字对的组合
箱体边缘的最小值和最大值;可以与
bins或binwidth一起使用。默认值为数据极值。- discrete布尔值
如果为 True,则默认使用
binwidth=1并绘制条形图,使其居中于其相应的数据点。这避免了使用离散(整数)数据时可能出现的“间隙”。- cumulative布尔值
如果为 True,则在箱体增加时绘制累积计数。
- common_bins布尔值
如果为 True,则当语义变量生成多个绘图时使用相同的箱体。如果使用参考规则来确定箱体,则它将使用完整的数据集进行计算。
- common_norm布尔值
如果为 True 且使用归一化的统计量,则归一化将应用于整个数据集。否则,独立地归一化每个直方图。
- multiple{“layer”, “dodge”, “stack”, “fill”}
当语义映射创建子集时,解决多个元素的方法。仅与单变量数据相关。
- element{“bars”, “step”, “poly”}
直方图统计量的视觉表示。仅与单变量数据相关。
- fill布尔值
如果为 True,则填充直方图下面的空间。仅与单变量数据相关。
- shrink数字
根据此因子,相对于箱体宽度缩放每个条形的宽度。仅与单变量数据相关。
- kde布尔值
如果为 True,则计算核密度估计以平滑分布并在绘图上显示为(一条或多条)线。仅与单变量数据相关。
- kde_kws字典
控制 KDE 计算的参数,如
kdeplot()中所述。- line_kws字典
控制 KDE 可视化的参数,传递给
matplotlib.axes.Axes.plot()。- thresh数字或 None
统计量小于或等于此值的单元格将是透明的。仅与双变量数据相关。
- pthresh数字或 None
与
thresh相似,但值为 [0, 1],使得总计不超过此比例的聚合计数(或其他统计量,在使用时)的单元格将是透明的。- pmax数字或 None
值为 [0, 1],在该值处为颜色映射设置饱和点,使得低于该值的单元格构成总计(或其他统计量,在使用时)的此比例。
- cbar布尔值
如果为 True,则添加颜色条以注释双变量绘图中的颜色映射。注意:目前不支持带有
hue变量的绘图。- cbar_ax
matplotlib.axes.Axes 颜色条的预先存在的轴。
- cbar_kws字典
传递给
matplotlib.figure.Figure.colorbar()的其他参数。- palette字符串、列表、字典或
matplotlib.colors.Colormap 用于选择在映射
hue语义时使用的颜色方法。字符串值传递给color_palette()。列表或字典值意味着分类映射,而颜色映射对象意味着数值映射。- hue_order字符串向量
指定
hue语义的分类级别处理和绘制的顺序。- hue_norm元组或
matplotlib.colors.Normalize 一对值,设置数据单位中的归一化范围,或者一个对象,将从数据单位映射到 [0, 1] 区间。使用意味着数值映射。
- color
matplotlib color 当未使用色调映射时使用的单个颜色规范。否则,绘图将尝试挂钩到 matplotlib 属性循环。
- log_scale布尔值或数字,或布尔值对或数字对
将轴刻度设置为对数。单个值设置绘图中任何数值轴的数据轴。一对值独立设置每个轴。数值解释为所需的基数(默认值为 10)。当为
None或False时,seaborn 会推迟到现有的 Axes 刻度。- legend布尔值
如果为 False,则抑制语义变量的图例。
- ax
matplotlib.axes.Axes 绘图的预先存在的轴。否则,在内部调用
matplotlib.pyplot.gca()。- kwargs
其他关键字参数传递给以下 matplotlib 函数之一
matplotlib.axes.Axes.bar()(单变量,element=”bars”)matplotlib.axes.Axes.fill_between()(单变量,其他元素,fill=True)matplotlib.axes.Axes.plot()(单变量,其他元素,fill=False)
- data
- 返回:
matplotlib.axes.Axes包含绘图的 matplotlib 轴。
另请参阅
注释
用于计算和绘制直方图的箱体选择会对从可视化中获得的见解产生重大影响。如果箱体太大,它们可能会抹去重要的特征。另一方面,太小的箱体可能会受到随机变化的支配,从而掩盖了真实潜在分布的形状。默认箱体大小是使用依赖于样本大小和方差的参考规则确定的。这在许多情况下效果很好(例如,在“行为良好的”数据情况下),但在其他情况下则失败。始终尝试不同的箱体大小以确保您没有错过任何重要的东西。此函数允许您通过多种方式指定箱体,例如设置要使用的箱体总数、每个箱体的宽度或箱体应断开的具体位置。
示例
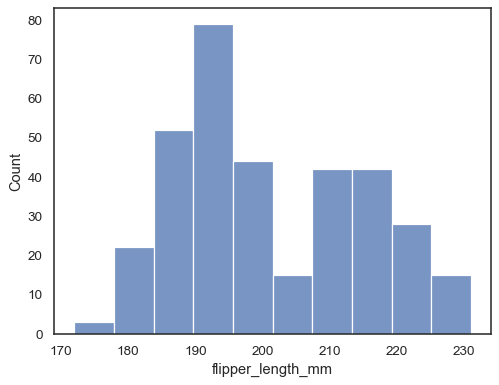
将一个变量分配给
x以绘制沿 x 轴的单变量分布penguins = sns.load_dataset("penguins") sns.histplot(data=penguins, x="flipper_length_mm")
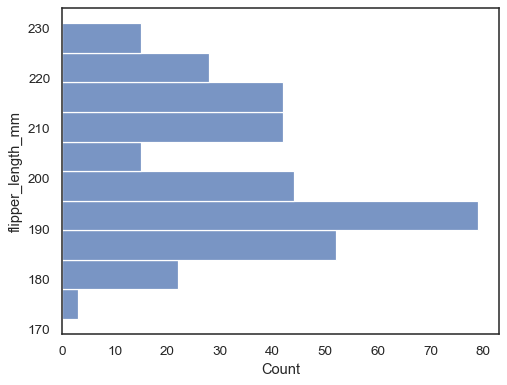
通过将数据变量分配给 y 轴来翻转绘图
sns.histplot(data=penguins, y="flipper_length_mm")
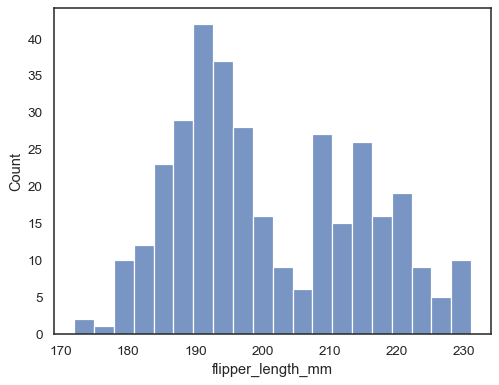
通过指定不同的箱体宽度来检查直方图如何很好地表示数据
sns.histplot(data=penguins, x="flipper_length_mm", binwidth=3)
您还可以定义要使用的箱体总数
sns.histplot(data=penguins, x="flipper_length_mm", bins=30)
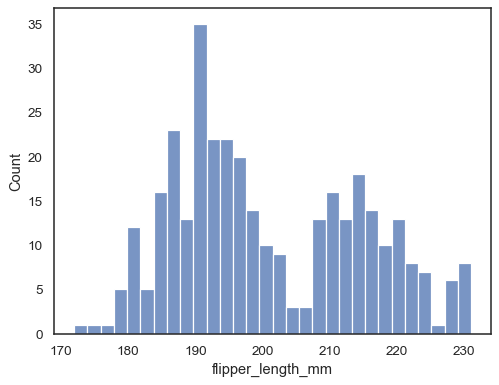
添加核密度估计以平滑直方图,提供有关分布形状的补充信息
sns.histplot(data=penguins, x="flipper_length_mm", kde=True)
如果既没有分配
x也没有分配y,则数据集将被视为宽格式,并且将为每个数值列绘制直方图sns.histplot(data=penguins)
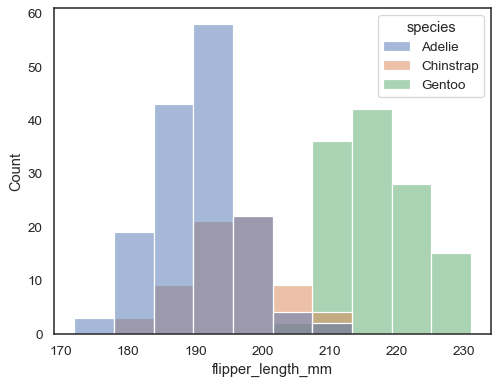
您可以使用色调映射从长格式数据集中绘制多个直方图
sns.histplot(data=penguins, x="flipper_length_mm", hue="species")
绘制多个分布的默认方法是“分层”,但您也可以“堆叠”它们
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")
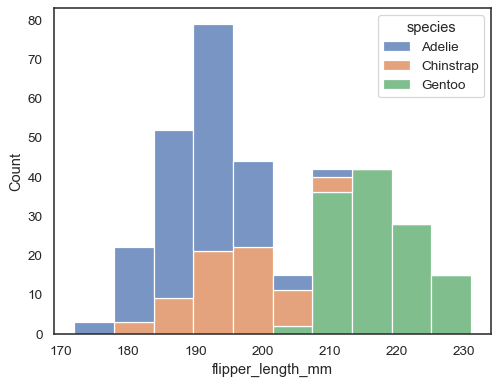
重叠的条形图在视觉上难以分辨。另一种方法是绘制阶梯函数
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="step")
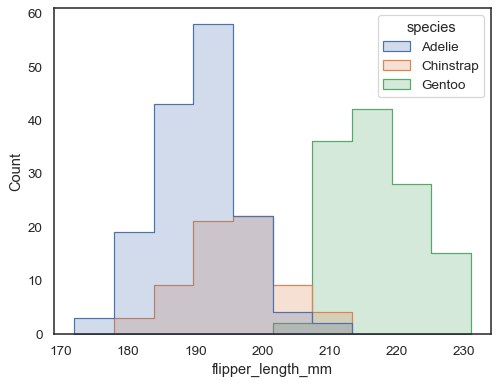
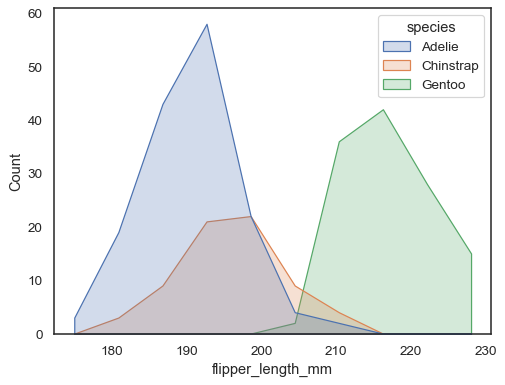
您可以通过绘制在每个箱体的中心具有顶点的多边形来进一步远离条形图。这可能会更容易看到分布的形状,但要谨慎使用:对于您的观众来说,他们正在查看直方图会不太明显
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="poly")
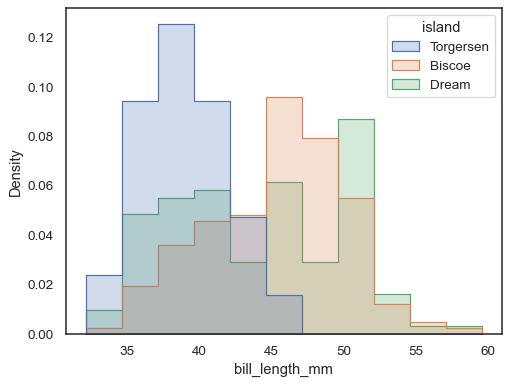
要比较大小差异很大的子集的分布,请使用独立密度归一化
sns.histplot( penguins, x="bill_length_mm", hue="island", element="step", stat="density", common_norm=False, )
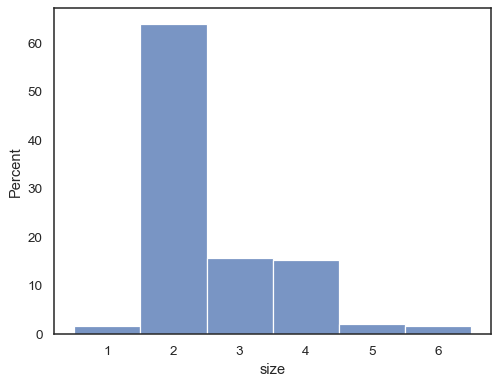
还可以进行归一化,以便每个条形的高度显示概率、比例或百分比,这对于离散变量更有意义
tips = sns.load_dataset("tips") sns.histplot(data=tips, x="size", stat="percent", discrete=True)
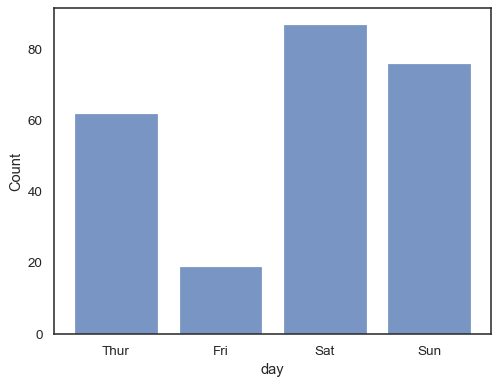
您甚至可以在分类变量上绘制直方图(尽管这是一个实验性功能)
sns.histplot(data=tips, x="day", shrink=.8)
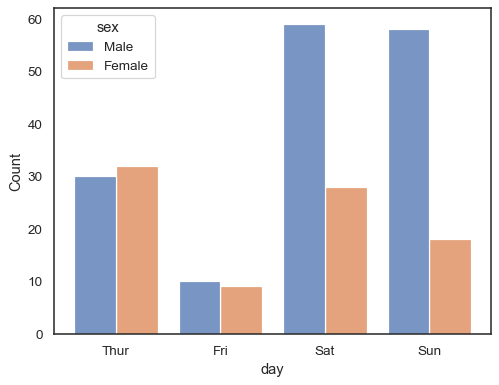
当使用离散数据的
hue语义时,对级别进行“躲避”可能是有意义的sns.histplot(data=tips, x="day", hue="sex", multiple="dodge", shrink=.8)
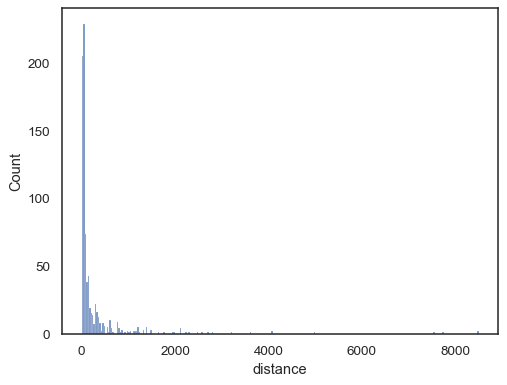
现实世界中的数据通常是倾斜的。对于高度倾斜的分布,最好在对数空间中定义箱体。比较
planets = sns.load_dataset("planets") sns.histplot(data=planets, x="distance")
与对数刻度版本
sns.histplot(data=planets, x="distance", log_scale=True)
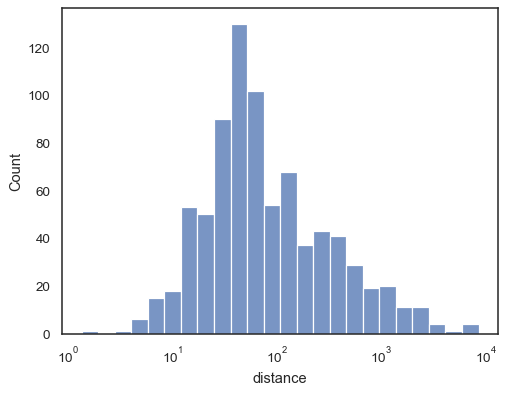
还有一些关于直方图外观的选项。您可以显示未填充的条形
sns.histplot(data=planets, x="distance", log_scale=True, fill=False)
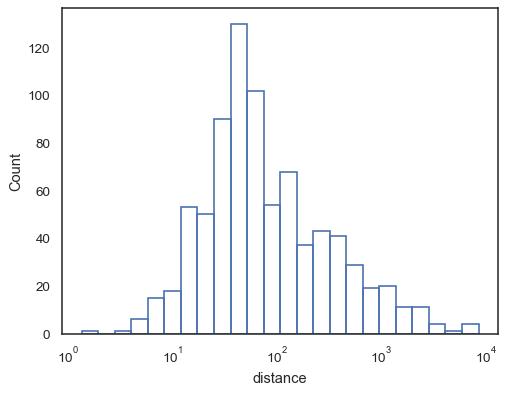
或未填充的阶梯函数
sns.histplot(data=planets, x="distance", log_scale=True, element="step", fill=False)
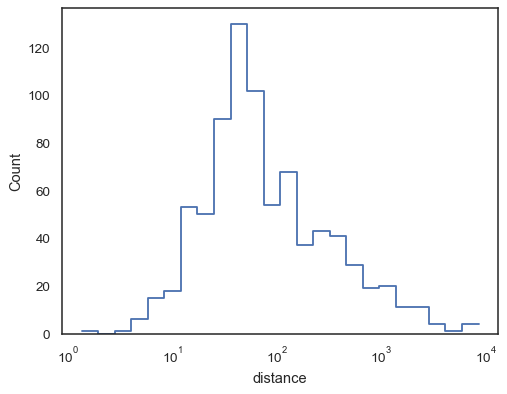
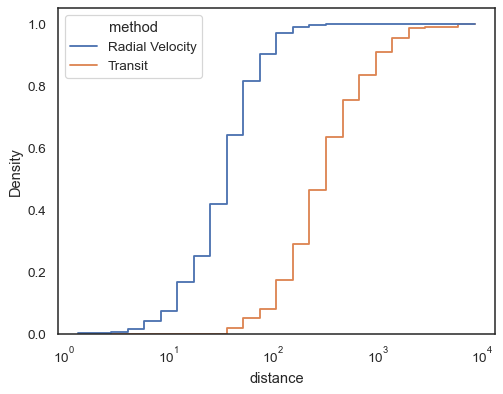
阶梯函数,尤其是当未填充时,可以轻松比较累积直方图
sns.histplot( data=planets, x="distance", hue="method", hue_order=["Radial Velocity", "Transit"], log_scale=True, element="step", fill=False, cumulative=True, stat="density", common_norm=False, )
当
x和y都被赋值时,将会计算一个双变量直方图,并以热图的形式显示。sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g")
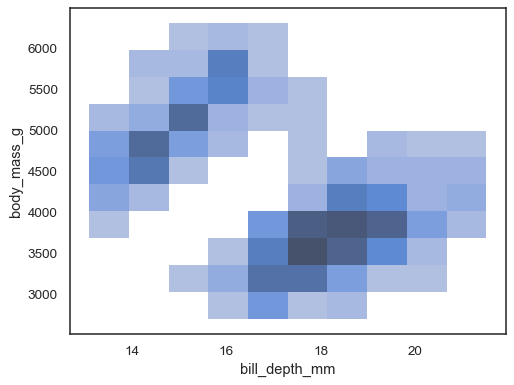
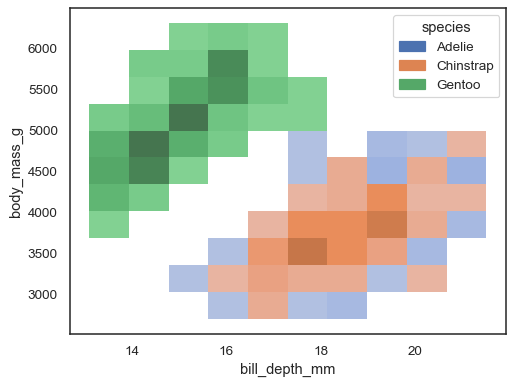
也可以指定一个
hue变量,但如果不同级别的数据有大量的重叠,这种方法效果可能不佳。sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g", hue="species")
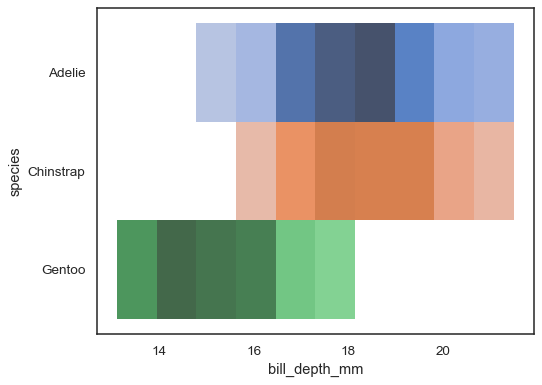
当其中一个变量是离散变量时,使用多个颜色映射可能会更合理。
sns.histplot( penguins, x="bill_depth_mm", y="species", hue="species", legend=False )
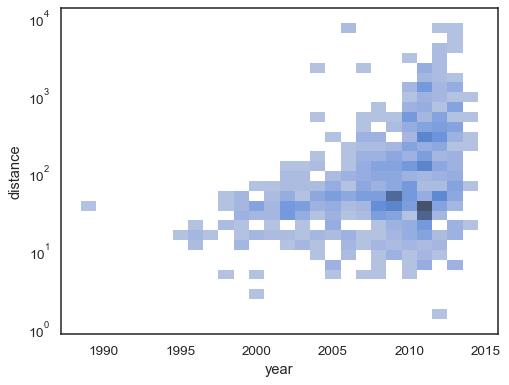
双变量直方图接受与其单变量对应直方图相同的计算选项,使用元组独立地参数化
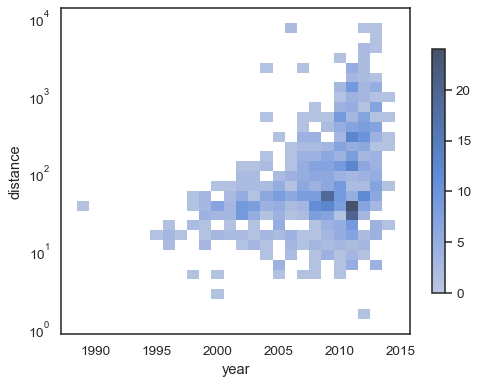
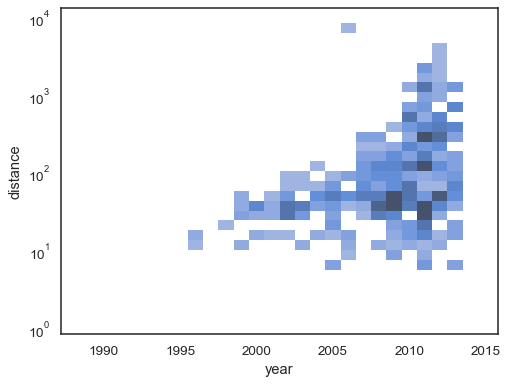
x和y。sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), )
默认情况下,没有观测值的单元格将被设置为透明,但这可以被禁用。
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), thresh=None, )
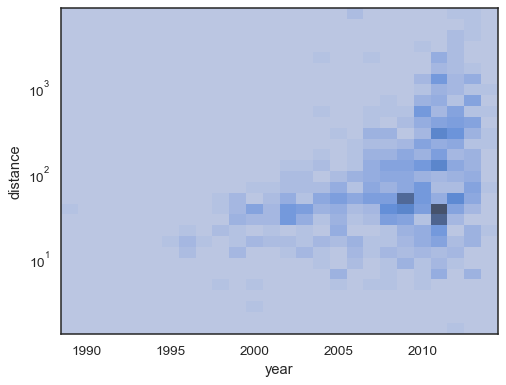
还可以根据累积计数的比例来设置阈值和颜色映射饱和点。
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), pthresh=.05, pmax=.9, )
要对颜色映射进行标注,请添加一个颜色条。
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), cbar=True, cbar_kws=dict(shrink=.75), )