seaborn.objects.Hist#
- class seaborn.objects.Hist(stat='count', bins='auto', binwidth=None, binrange=None, common_norm=True, common_bins=True, cumulative=False, discrete=False)#
对观测值进行分组,计算其数量,并可以选择进行归一化或累积。
- 参数:
- statstr
每个分组中要计算的聚合统计量
count: 观测值的数量density: 归一化,使得直方图的总面积等于1percent: 归一化,使得柱状图的高度之和为100probability或proportion: 归一化,使得柱状图的高度之和为1frequency: 将观测值数量除以分组宽度
- binsstr, int 或 ArrayLike
通用参数,可以是参考规则的名称、分组数量或分组边界。传递给
numpy.histogram_bin_edges().- binwidthfloat
每个分组的宽度;覆盖
bins,但可以与binrange一起使用。注意,如果binwidth不能均匀地划分分组范围,则实际使用的分组宽度将仅近似于参数值。- binrange(min, max)
分组边界的最小值和最大值;可以与
bins(当为数字时)或binwidth一起使用。默认为数据极值。- common_normbool 或变量列表
当不为
False时,归一化将应用于所有组。使用True对所有组进行归一化,或传递定义归一化组的变量名。- common_binsbool 或变量列表
当不为
False时,所有组使用相同的分组。使用True对所有组共享分组,或传递变量名以在其中共享分组。- cumulativebool
如果为 True,则累积分组值。
- discretebool
如果为 True,则设置
binwidth和binrange,使得分组宽度为单位宽度,并以整数为中心
备注
计算和绘制直方图的分组选择会对从可视化中得出的见解产生重大影响。如果分组过大,它们可能会抹去重要的特征。另一方面,分组过小可能会被随机变异性所支配,从而掩盖了真实潜在分布的形状。默认分组大小是使用参考规则确定的,该规则取决于样本大小和方差。这在许多情况下(例如,对于“行为良好的”数据)效果很好,但在其他情况下则失败。始终尝试不同的分组大小以确保您没有错过重要的内容。此函数允许您通过多种方式指定分组,例如通过设置要使用的分组总数、每个分组的宽度或分组应断裂的特定位置。
示例
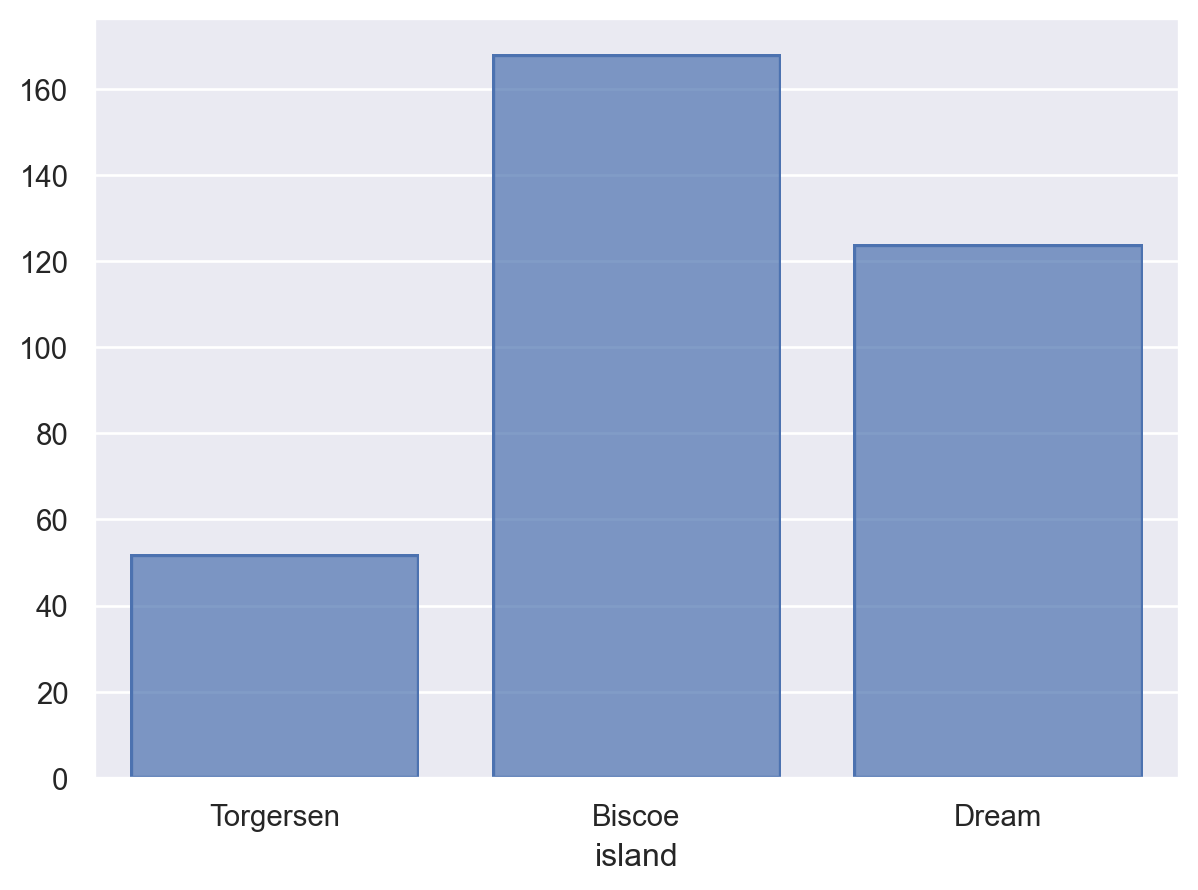
对于离散或分类变量,此统计量通常与
Bar标记组合使用so.Plot(penguins, "island").add(so.Bar(), so.Hist())
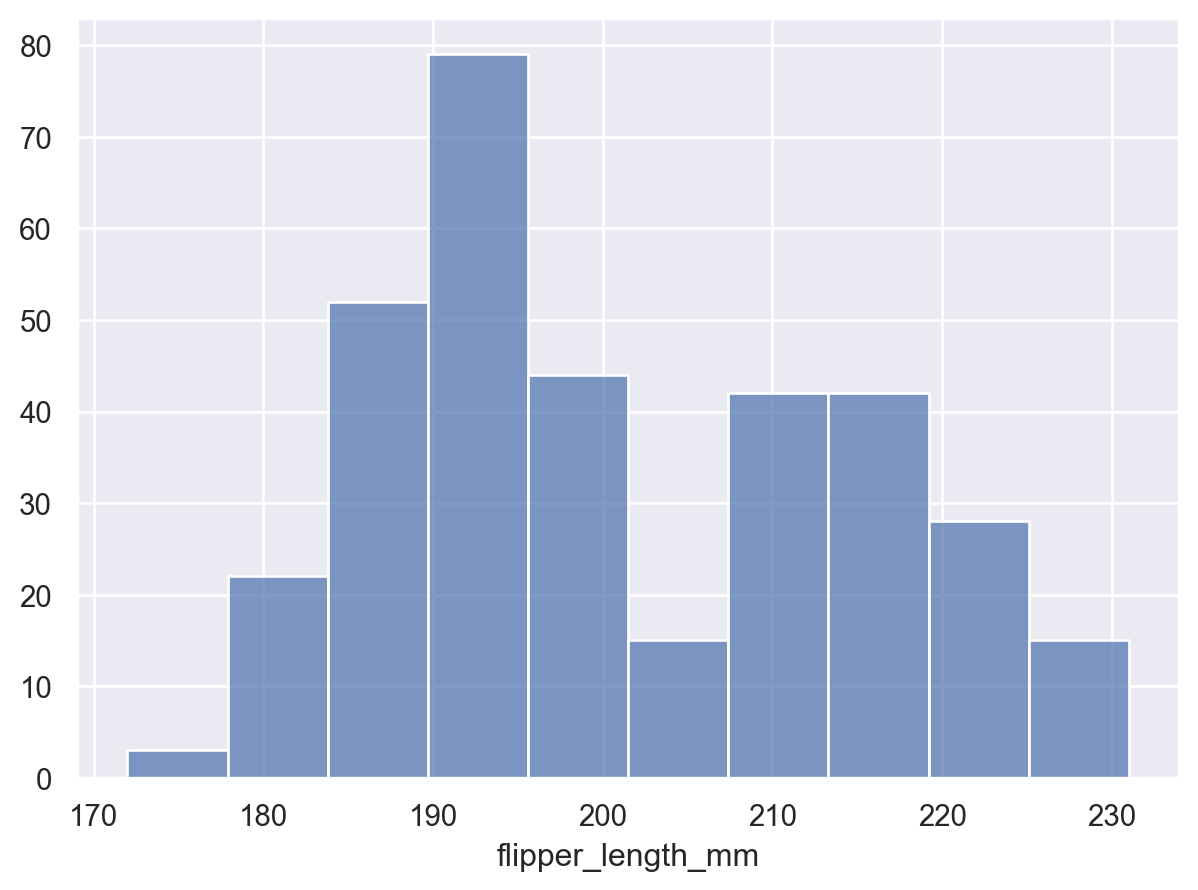
当用于估计单变量分布时,最好使用
Bars标记p = so.Plot(penguins, "flipper_length_mm") p.add(so.Bars(), so.Hist())
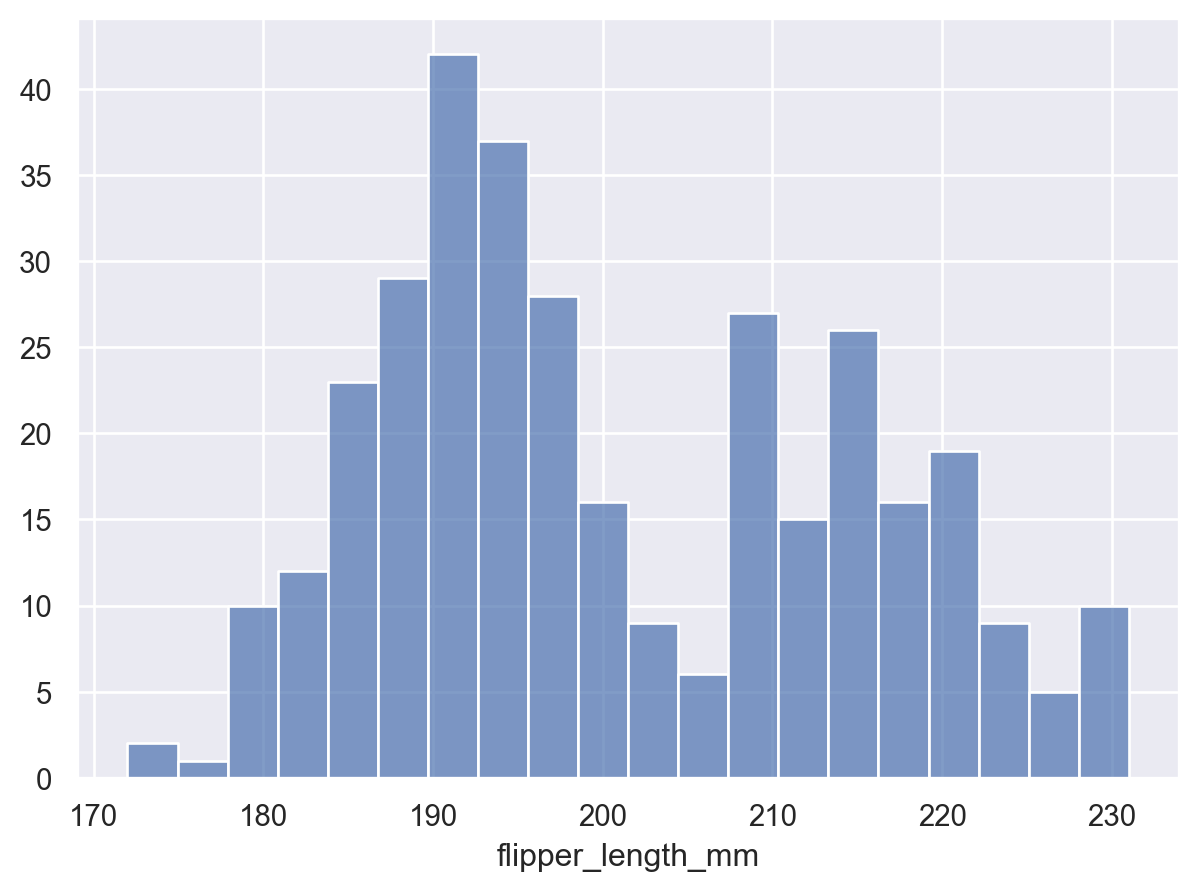
分组的粒度会影响潜在分布是否得到准确地表示。通过设置总数来调整它
p.add(so.Bars(), so.Hist(bins=20))
或者,指定分组的宽度
p.add(so.Bars(), so.Hist(binwidth=5))
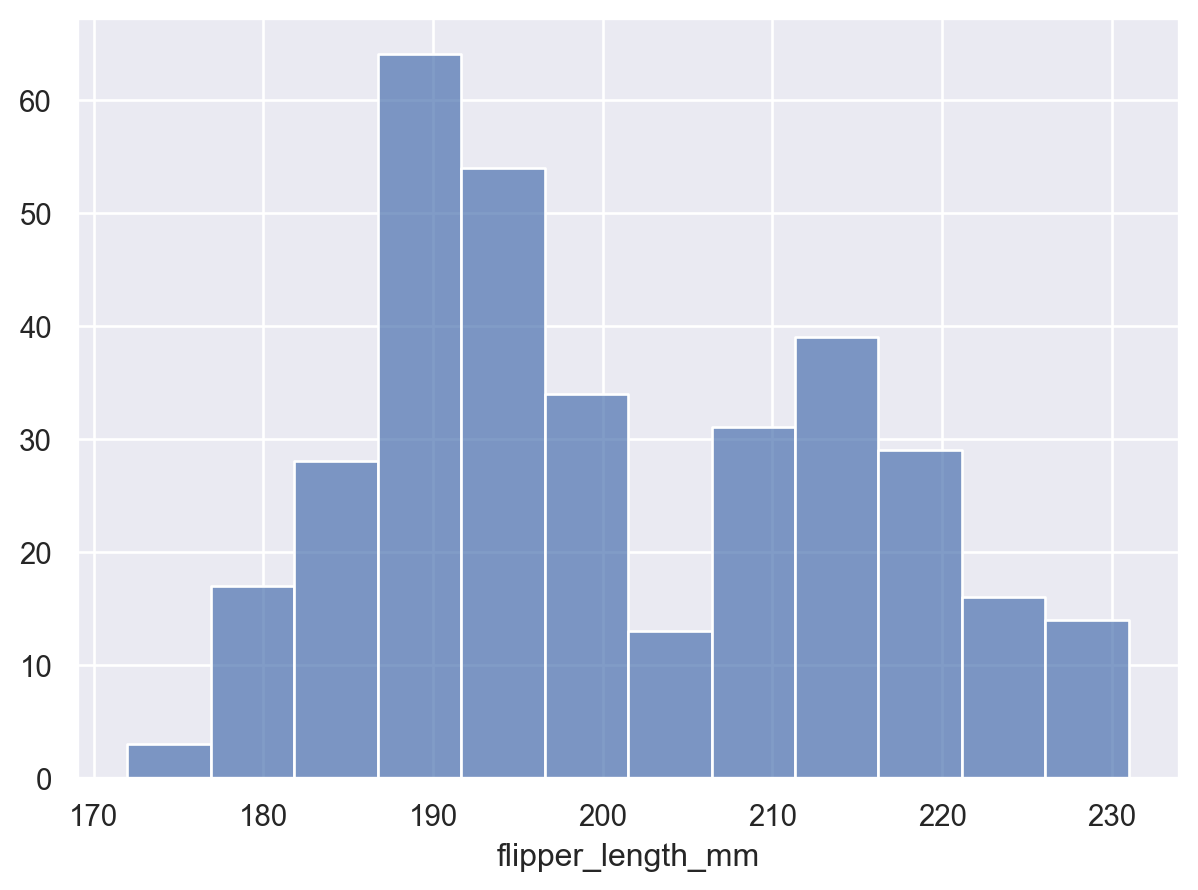
默认情况下,变换返回每个分组中观测值的计数。计数可以进行归一化,例如显示比例
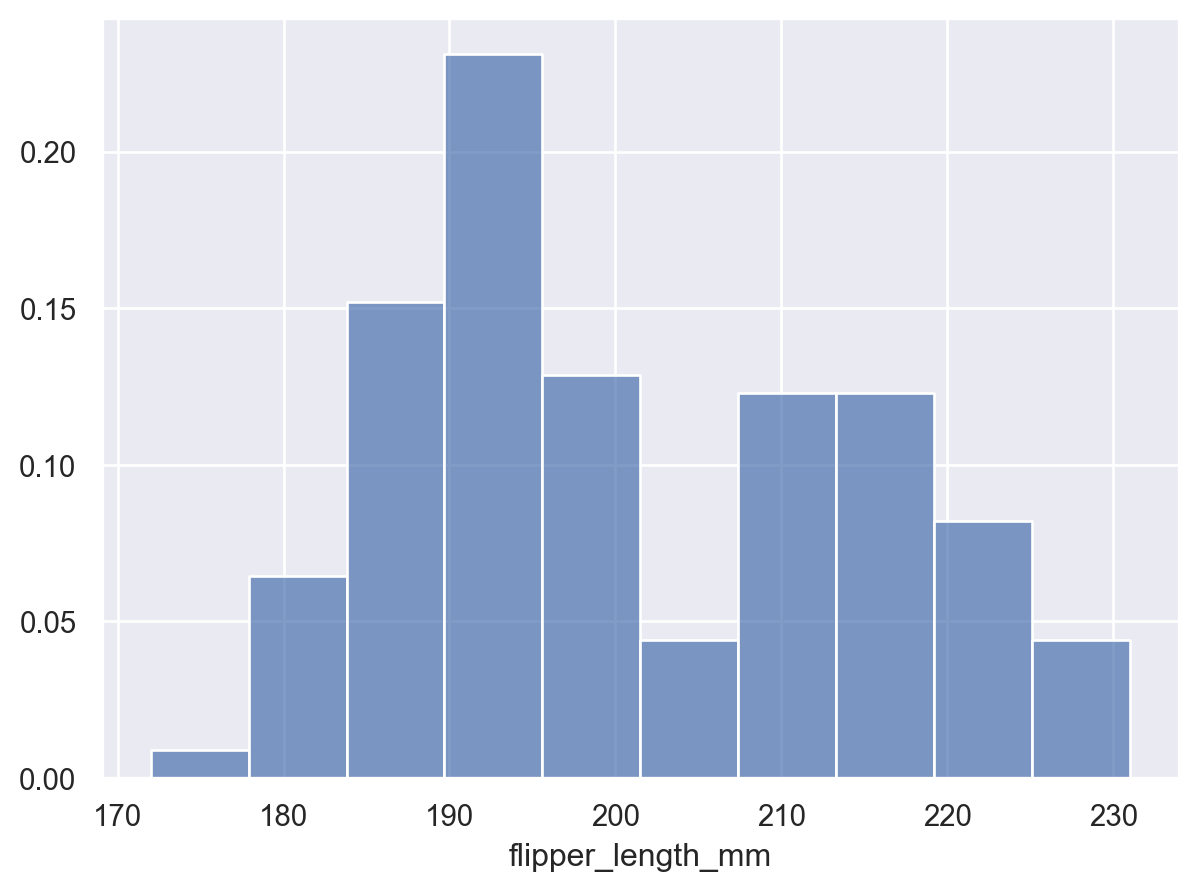
p.add(so.Bars(), so.Hist(stat="proportion"))
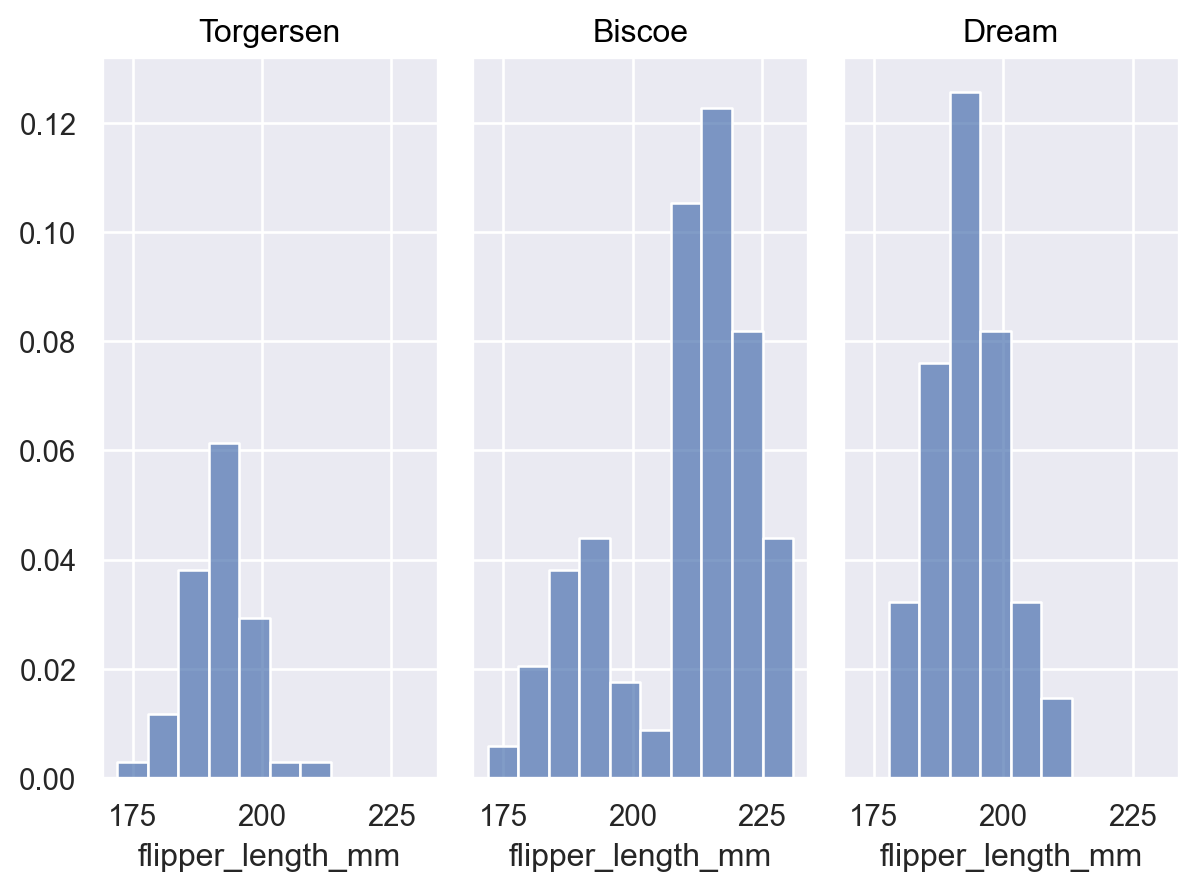
当其他变量定义组时,默认行为是对所有组进行归一化
p = p.facet("island") p.add(so.Bars(), so.Hist(stat="proportion"))
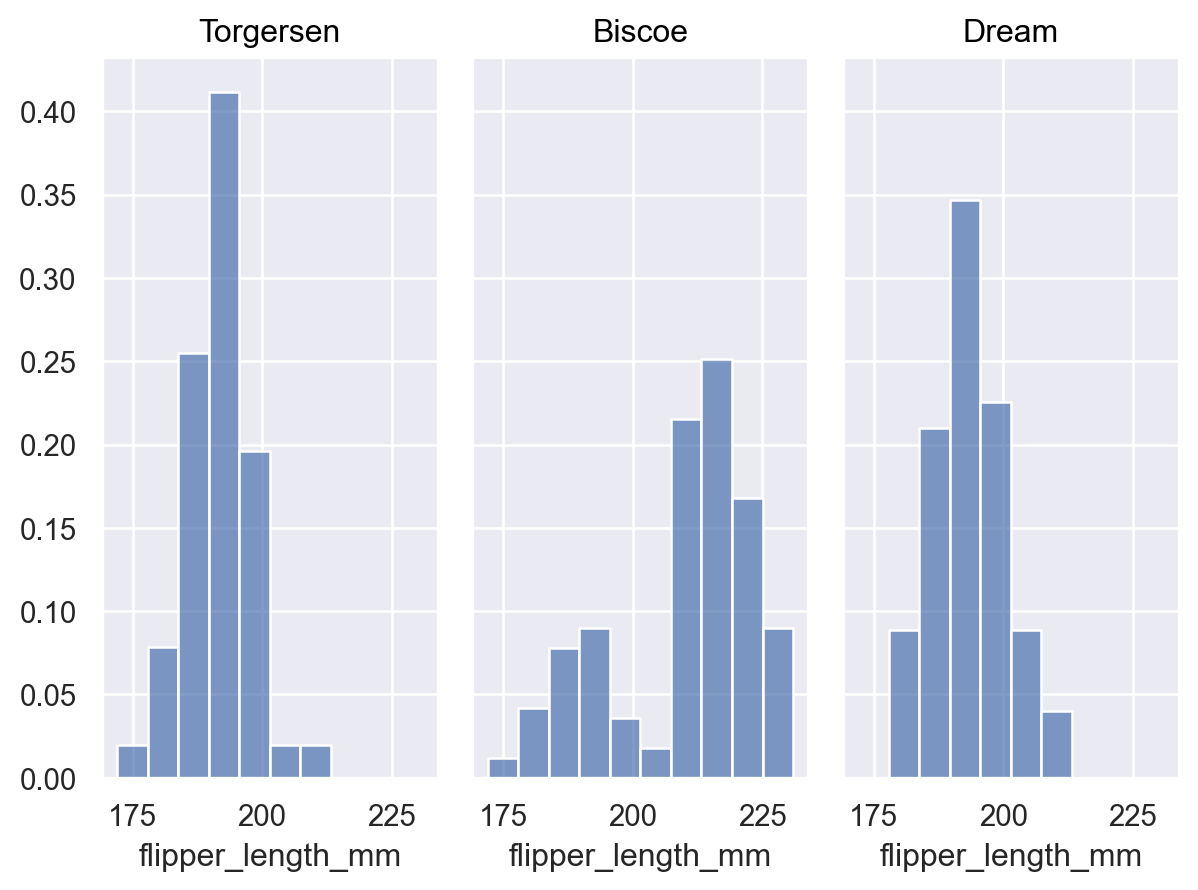
传递
common_norm=False以独立地对每个分布进行归一化p.add(so.Bars(), so.Hist(stat="proportion", common_norm=False))
或者,在多个分组变量的情况下,指定一个子集以在其中进行归一化
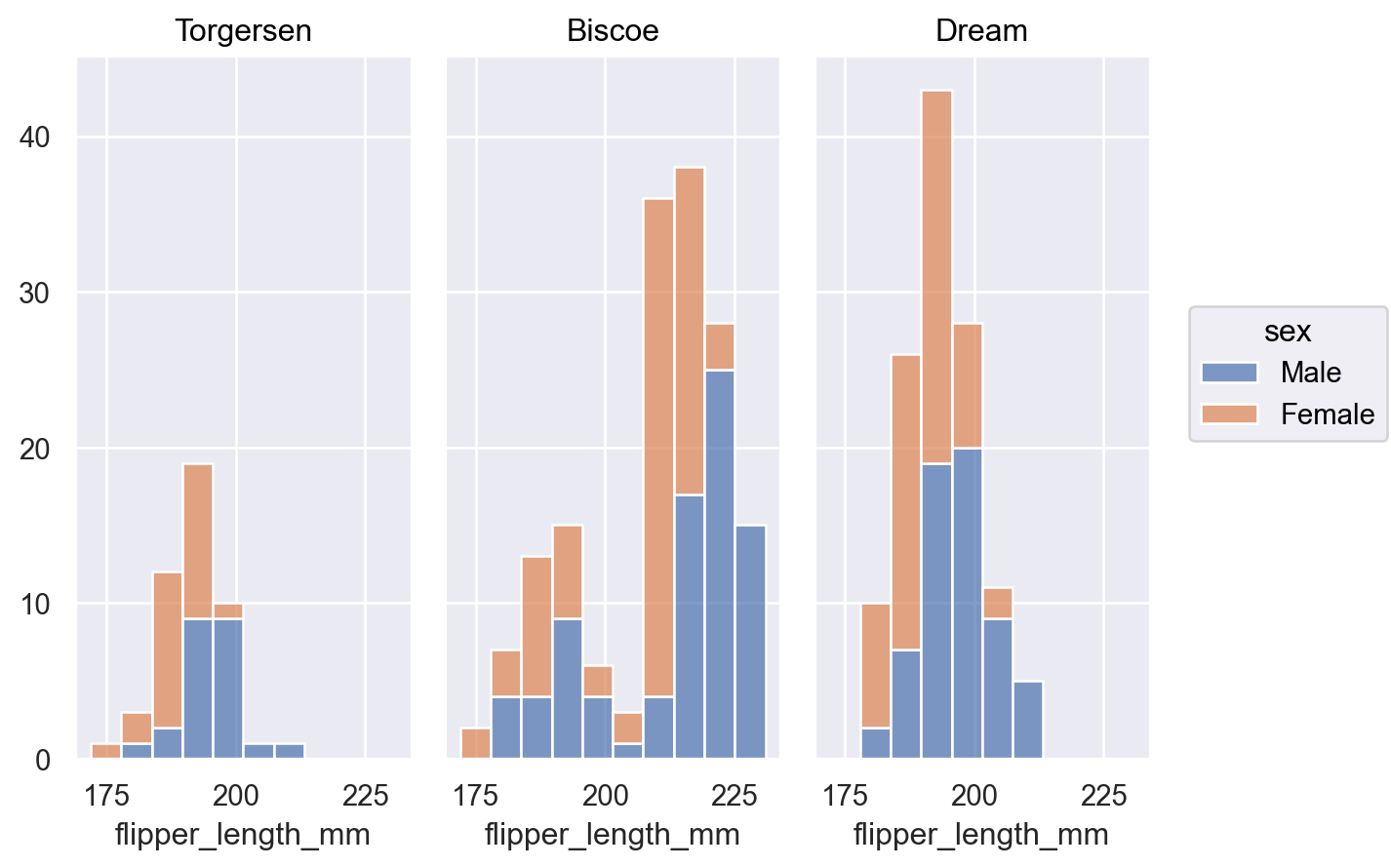
p.add(so.Bars(), so.Hist(stat="proportion", common_norm=["col"]), color="sex")
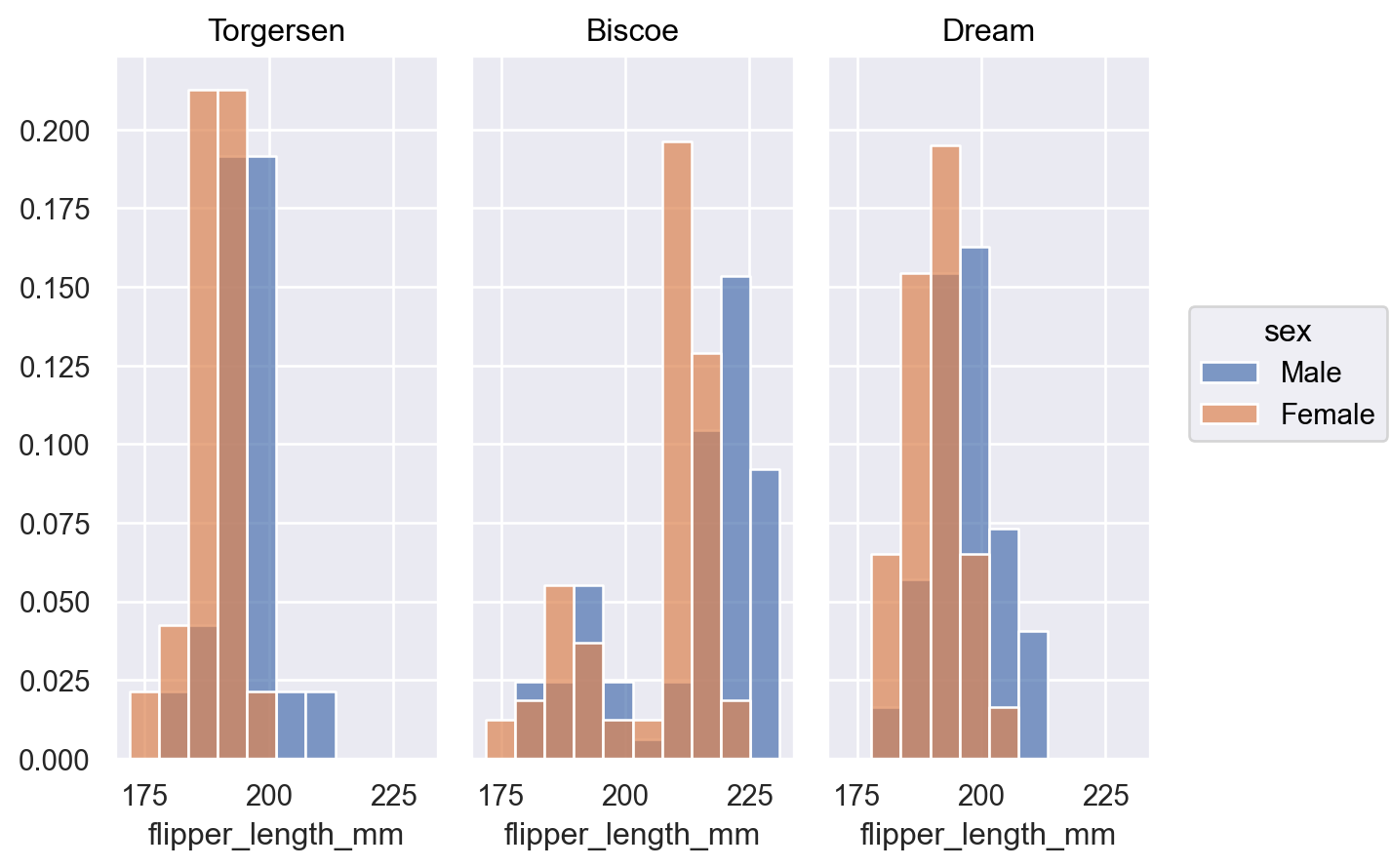
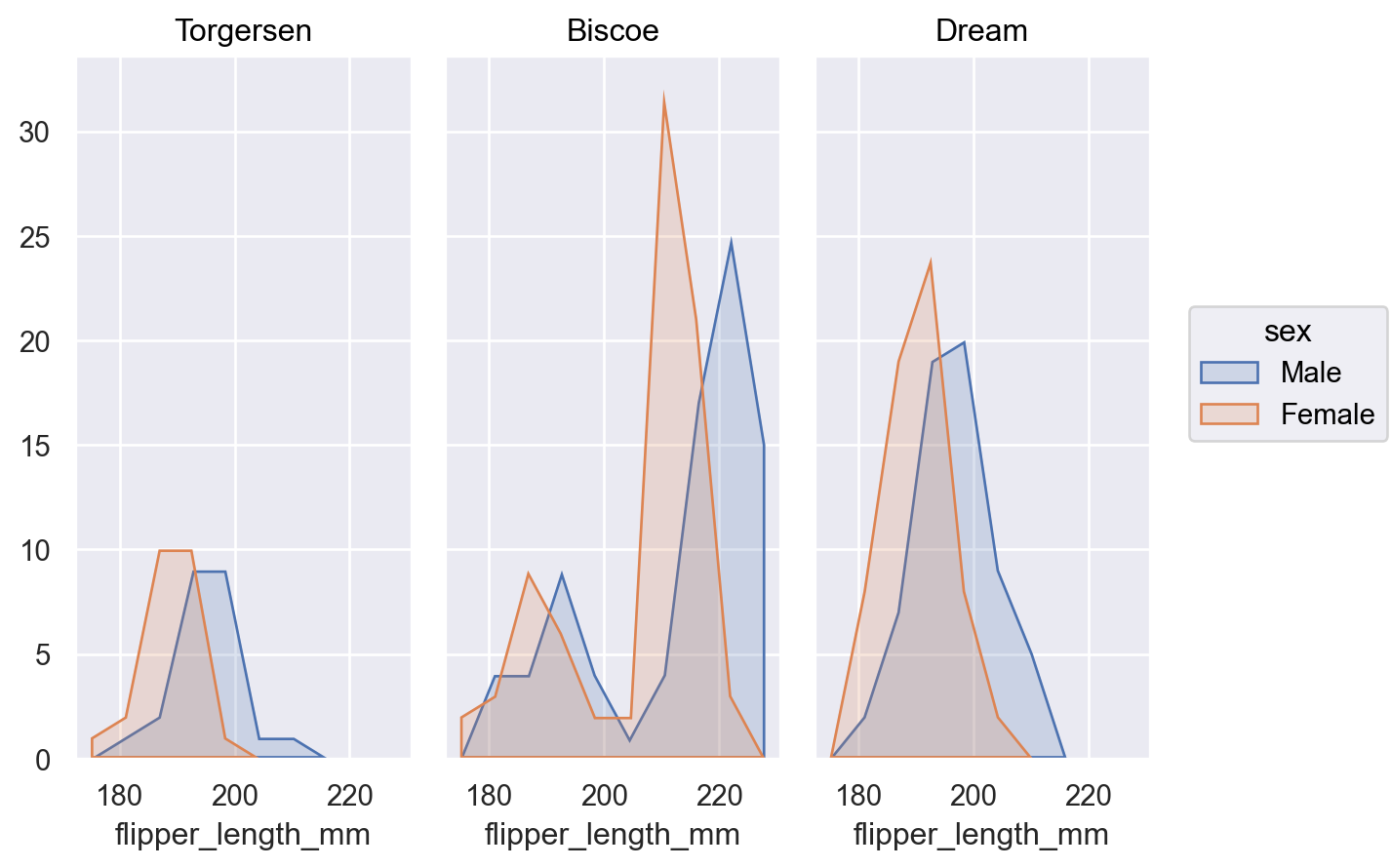
当分布重叠时,使用
Area标记更容易识别其形状p.add(so.Area(), so.Hist(), color="sex")
或添加
Stack移动以表示部分与整体的关系p.add(so.Bars(), so.Hist(), so.Stack(), color="sex")