seaborn.kdeplot#
- seaborn.kdeplot(data=None, *, x=None, y=None, hue=None, weights=None, palette=None, hue_order=None, hue_norm=None, color=None, fill=None, multiple='layer', common_norm=True, common_grid=False, cumulative=False, bw_method='scott', bw_adjust=1, warn_singular=True, log_scale=None, levels=10, thresh=0.05, gridsize=200, cut=3, clip=None, legend=True, cbar=False, cbar_ax=None, cbar_kws=None, ax=None, **kwargs)#
使用核密度估计绘制单变量或双变量分布。
核密度估计 (KDE) 图是一种可视化数据集观测分布的方法,类似于直方图。KDE 使用一维或多维的连续概率密度曲线来表示数据。
该方法在 用户指南 中有更详细的解释。
与直方图相比,KDE 可以生成更简洁、更易于解释的图,尤其是在绘制多个分布时。但如果底层分布有界或不平滑,它可能会引入失真。与直方图一样,表示的质量也取决于对良好平滑参数的选择。
- 参数:
- data
pandas.DataFrame,numpy.ndarray, 映射或序列 输入数据结构。可以分配给命名变量的长格式向量集合或将被内部重塑的宽格式数据集。
- x, y向量或
data中的键 指定 x 轴和 y 轴上的位置的变量。
- hue向量或
data中的键 映射以确定绘图元素颜色的语义变量。
- weights向量或
data中的键 如果提供,则使用这些值对核密度估计进行加权。
- palette字符串、列表、字典或
matplotlib.colors.Colormap 用于选择在映射
hue语义时使用的颜色的方法。字符串值被传递给color_palette()。列表或字典值表示分类映射,而颜色图对象表示数值映射。- hue_order字符串向量
指定
hue语义的分类级别的处理和绘制顺序。- hue_norm元组或
matplotlib.colors.Normalize 一对值,用于设置数据单位中的归一化范围,或一个将数据单位映射到 [0, 1] 区间中的对象。使用表示数值映射。
- color
matplotlib color 当不使用色调映射时,用于单一颜色规范。否则,绘图将尝试连接到 matplotlib 属性循环。
- fill布尔值或 None
如果为 True,则填充单变量密度曲线下的区域或双变量等高线之间的区域。如果为 None,则默认值取决于
multiple。- multiple{{“layer”, “stack”, “fill”}}
当语义映射创建子集时,用于绘制多个元素的方法。仅与单变量数据相关。
- common_norm布尔值
如果为 True,则将每个条件密度按观察次数进行缩放,使所有密度下的总面积之和为 1。否则,独立地归一化每个密度。
- common_grid布尔值
如果为 True,则对每个核密度估计使用相同的评估网格。仅与单变量数据相关。
- cumulative布尔值,可选
如果为 True,则估计累积分布函数。需要 scipy。
- bw_method字符串、标量或可调用对象,可选
用于确定要使用的平滑带宽的方法;传递给
scipy.stats.gaussian_kde.- bw_adjust数字,可选
一个因子,乘以使用
bw_method选择的值。增加将使曲线更平滑。见说明。- warn_singular布尔值
如果为 True,则在尝试估计方差为零的数据的密度时发出警告。
- log_scale布尔值或数字,或布尔值或数字对
将轴刻度设置为对数。单个值设置绘图中任何数值轴的数据轴。一对值独立地设置每个轴。数值解释为所需的底数(默认值为 10)。当为
None或False时,seaborn 会延迟到现有的 Axes 刻度。- levels整数或向量
要绘制等高线的等高线数量或值。向量参数必须具有 [0, 1] 中的递增值。级别对应于密度的等比例:例如,20% 的概率质量将位于绘制为 0.2 的等高线以下。仅与双变量数据相关。
- thresh[0, 1] 中的数字
绘制等高线的最低等比例水平。当
levels为向量时,将被忽略。仅与双变量数据相关。- gridsize整数
评估网格每个维度上的点数。
- cut数字,可选
因子,乘以平滑带宽,确定评估网格扩展到极端数据点的距离。当设置为 0 时,在数据限制处截断曲线。
- clip数字对或 None,或此类对对
不要在这些限制之外评估密度。
- legend布尔值
如果为 False,则抑制语义变量的图例。
- cbar布尔值
如果为 True,则添加一个颜色条以在双变量图中注释颜色映射。注意:目前不支持带有
hue变量的绘图。- cbar_ax
matplotlib.axes.Axes 颜色条的预先存在的轴。
- cbar_kws字典
传递给
matplotlib.figure.Figure.colorbar()的其他参数。- ax
matplotlib.axes.Axes 绘图的预先存在的轴。否则,在内部调用
matplotlib.pyplot.gca().- kwargs
其他关键字参数将传递给以下 matplotlib 函数之一
matplotlib.axes.Axes.plot()(单变量,fill=False),matplotlib.axes.Axes.fill_between()(单变量,fill=True),matplotlib.axes.Axes.contour()(双变量,fill=False),matplotlib.axes.contourf()(双变量,fill=True)。
- data
- 返回值:
matplotlib.axes.Axes包含绘图的 matplotlib 轴。
另请参阅
displot用于分布图函数的图级界面。
histplot绘制带可选归一化或平滑的直方图。
ecdfplot绘制经验累积分布函数。
jointplot绘制带有单变量边缘分布的双变量图。
violinplot使用核密度估计绘制增强的箱线图。
说明
带宽,或平滑核的标准差,是一个重要的参数。带宽的错误指定会导致数据表示失真。与直方图中箱宽的选择类似,过度平滑的曲线会抹去分布的真实特征,而过度平滑的曲线会在随机变异中创建虚假特征。设置默认带宽的经验法则在真实分布平滑、单峰且大致呈钟形时效果最佳。始终建议使用
bw_adjust增加或减少平滑量来检查默认行为。由于平滑算法使用高斯核,因此估计的密度曲线可以扩展到对特定数据集没有意义的值。例如,当平滑自然为正的数据时,曲线可能会绘制在负值之上。可以使用
cut和clip参数来控制曲线的范围,但具有许多靠近自然边界的观测值的数据集可能更适合使用其他可视化方法。当数据集自然离散或“尖峰”(包含许多相同值的重复观测值)时,也会出现类似的考虑因素。核密度估计总是会产生一条平滑曲线,这在这些情况下会产生误导。
密度轴上的单位是常见的混淆来源。虽然核密度估计会产生概率分布,但曲线在每个点的高度给出密度,而不是概率。概率只能通过对密度在一个范围内进行积分来获得。曲线被归一化,以便在所有可能的值上的积分等于 1,这意味着密度轴的刻度取决于数据值。
示例
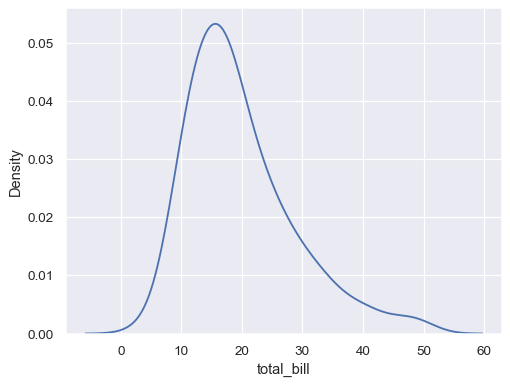
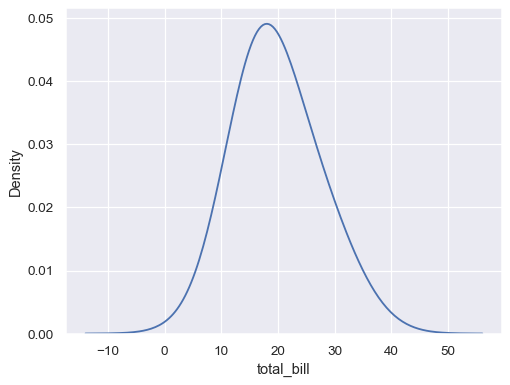
在 x 轴上绘制单变量分布
tips = sns.load_dataset("tips") sns.kdeplot(data=tips, x="total_bill")
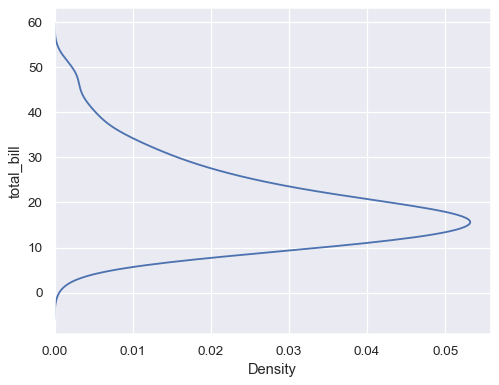
通过将数据变量分配给 y 轴来翻转绘图
sns.kdeplot(data=tips, y="total_bill")
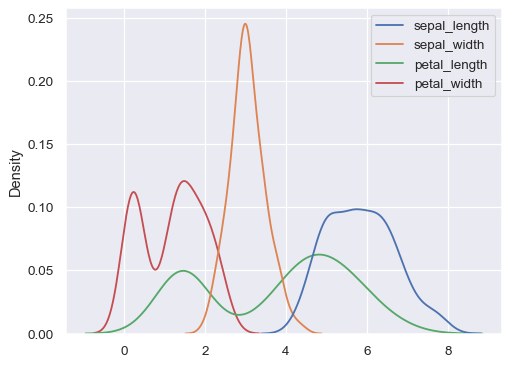
绘制宽格式数据集的每一列的分布
iris = sns.load_dataset("iris") sns.kdeplot(data=iris)
使用较少的平滑
sns.kdeplot(data=tips, x="total_bill", bw_adjust=.2)
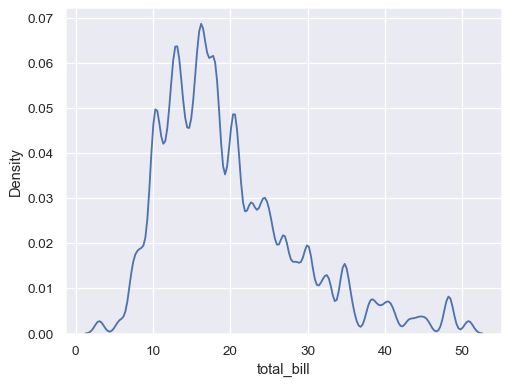
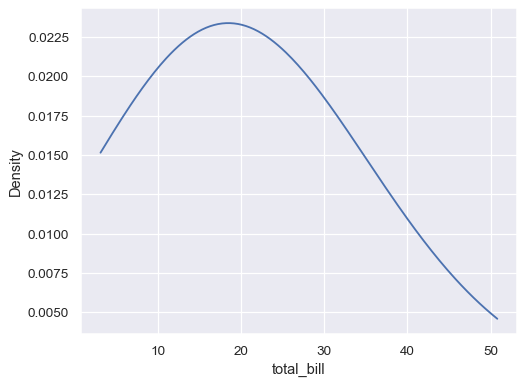
使用更多平滑,但不要平滑到极端数据点之外
ax= sns.kdeplot(data=tips, x="total_bill", bw_adjust=5, cut=0)
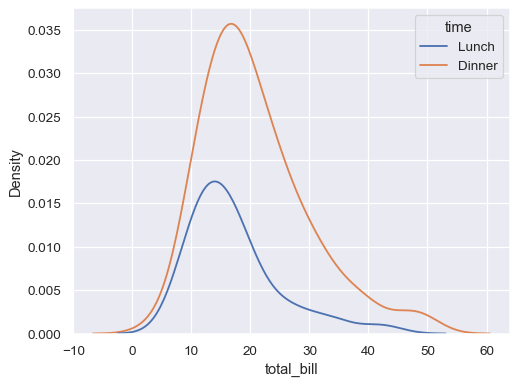
绘制条件分布,其中第二个变量具有色调映射
sns.kdeplot(data=tips, x="total_bill", hue="time")
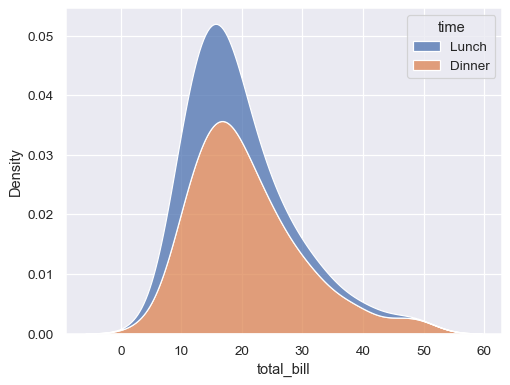
“堆叠”条件分布
sns.kdeplot(data=tips, x="total_bill", hue="time", multiple="stack")
在网格中的每个值处归一化堆叠分布
sns.kdeplot(data=tips, x="total_bill", hue="time", multiple="fill")
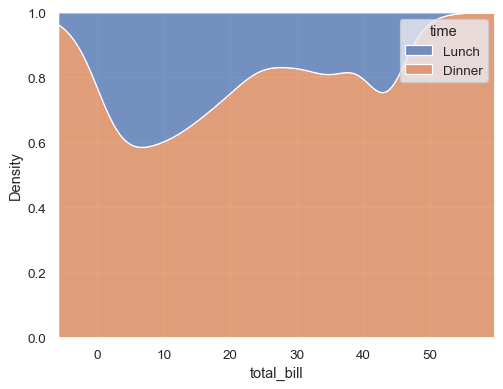
估计累积分布函数,归一化每个子集
sns.kdeplot( data=tips, x="total_bill", hue="time", cumulative=True, common_norm=False, common_grid=True, )
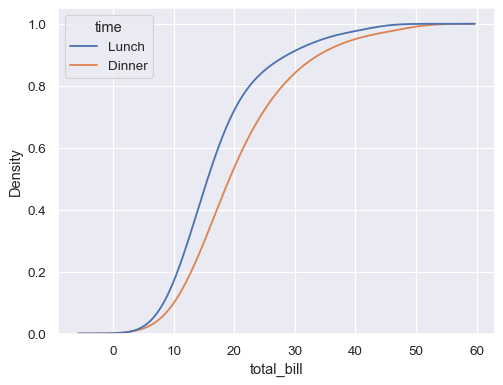
从聚合数据估计分布,使用权重
tips_agg = (tips .groupby("size") .agg(total_bill=("total_bill", "mean"), n=("total_bill", "count")) ) sns.kdeplot(data=tips_agg, x="total_bill", weights="n")
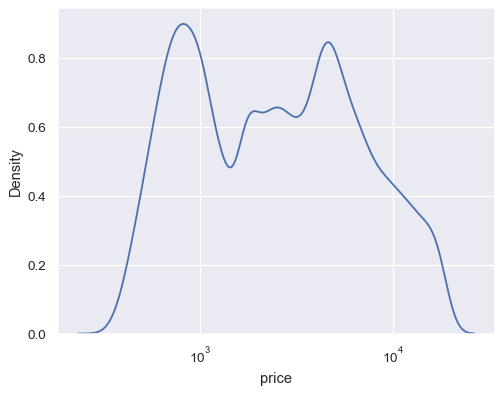
使用对数缩放映射数据变量
diamonds = sns.load_dataset("diamonds") sns.kdeplot(data=diamonds, x="price", log_scale=True)
使用数值色调映射
sns.kdeplot(data=tips, x="total_bill", hue="size")
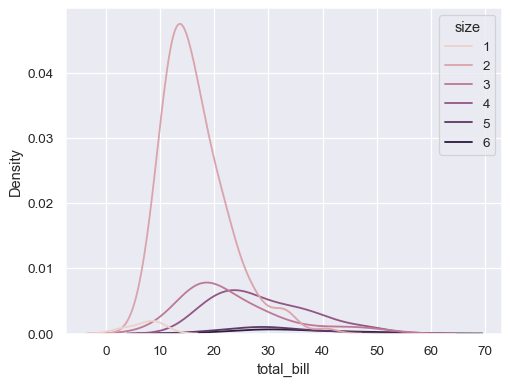
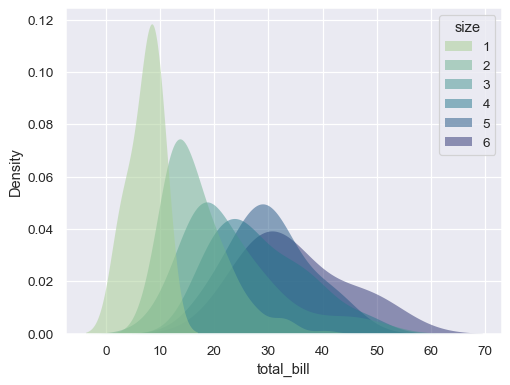
修改绘图的外观
sns.kdeplot( data=tips, x="total_bill", hue="size", fill=True, common_norm=False, palette="crest", alpha=.5, linewidth=0, )
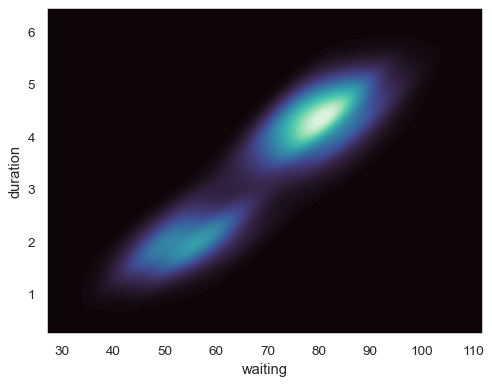
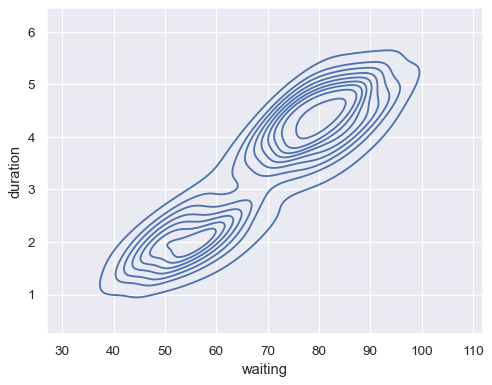
绘制双变量分布
geyser = sns.load_dataset("geyser") sns.kdeplot(data=geyser, x="waiting", y="duration")
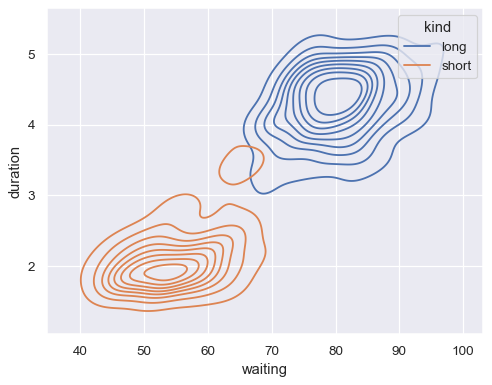
使用色调语义映射第三个变量以显示条件分布
sns.kdeplot(data=geyser, x="waiting", y="duration", hue="kind")
显示填充的等高线
sns.kdeplot( data=geyser, x="waiting", y="duration", hue="kind", fill=True, )
显示更少的等高线级别,覆盖更少的分布
sns.kdeplot( data=geyser, x="waiting", y="duration", hue="kind", levels=5, thresh=.2, )
使用不同的颜色图,用平滑分布填充轴范围
sns.kdeplot( data=geyser, x="waiting", y="duration", fill=True, thresh=0, levels=100, cmap="mako", )