seaborn.clustermap#
- seaborn.clustermap(data, *, pivot_kws=None, method='average', metric='euclidean', z_score=None, standard_scale=None, figsize=(10, 10), cbar_kws=None, row_cluster=True, col_cluster=True, row_linkage=None, col_linkage=None, row_colors=None, col_colors=None, mask=None, dendrogram_ratio=0.2, colors_ratio=0.03, cbar_pos=(0.02, 0.8, 0.05, 0.18), tree_kws=None, **kwargs)#
将矩阵数据集绘制为层次聚类热图。
此函数需要 scipy 可用。
- 参数:
- data2D 数组类
用于聚类的矩形数据。不能包含 NAs。
- pivot_kws字典,可选
如果
data是一个整洁的数据框,可以提供关键字参数用于 pivot 来创建一个矩形数据框。- method字符串,可选
用于计算聚类的连接方法。有关更多信息,请参阅
scipy.cluster.hierarchy.linkage()文档。- metric字符串,可选
用于数据的距离度量。有关更多选项,请参阅
scipy.spatial.distance.pdist()文档。要对行和列使用不同的度量(或方法),您可以自行构建每个连接矩阵,并将它们提供为{row,col}_linkage。- z_score整数或无,可选
0(行)或 1(列)。是否要计算行或列的 z 分数。z 分数为:z = (x - mean)/std,因此每行(列)中的值将减去行(列)的平均值,然后除以行(列)的标准差。这确保每行(列)的平均值为 0,方差为 1。
- standard_scale整数或无,可选
0(行)或 1(列)。是否要标准化该维度,这意味着对于每行或列,减去最小值,然后除以其最大值。
- figsize(宽度,高度)元组,可选
图形的总体大小。
- cbar_kws字典,可选
要传递给
cbar_kws的关键字参数heatmap(),例如,要为颜色条添加标签。- {row,col}_cluster布尔值,可选
如果
True,则聚类 {行,列}。- {row,col}_linkage
numpy.ndarray,可选 行或列的预先计算的连接矩阵。有关特定格式,请参阅
scipy.cluster.hierarchy.linkage()。- {row,col}_colors列表类或 pandas 数据框/序列,可选
用于标记行或列的颜色列表。用于评估组内的样本是否聚集在一起。可以使用嵌套列表或数据框来进行多个颜色级别标记。如果以
pandas.DataFrame或pandas.Series的形式给出,则颜色的标签是从数据框的列名或序列的名称中提取的。数据框/序列颜色也与其索引匹配,确保颜色按正确的顺序绘制。- mask布尔数组或数据框,可选
如果传递,则当
mask为 True 时,数据将不会显示在单元格中。具有缺失值的单元格会自动被屏蔽。仅用于可视化,不用于计算。- {dendrogram,colors}_ratio浮点数,或浮点数对,可选
分配给两个边际元素的图形大小比例。如果给出对,则它们对应于 (row, col) 比例。
- cbar_pos(左,下,宽,高)元组,可选
图形中颜色条轴的位置。设置为
None将禁用颜色条。- tree_kws字典,可选
用于
matplotlib.collections.LineCollection的参数,用于绘制树状图的线条。- kwargs其他关键字参数
所有其他关键字参数将传递给
heatmap()。
- 返回值:
ClusterGrid一个
ClusterGrid实例。
另请参阅
heatmap将矩形数据绘制为颜色编码矩阵。
注意
返回的对象具有一个
savefig方法,如果您想保存图形对象而不裁剪树状图,则应使用该方法。要访问重新排序的行索引,请使用:
clustergrid.dendrogram_row.reordered_ind列索引,请使用:
clustergrid.dendrogram_col.reordered_ind示例
绘制具有行和列聚类的热图
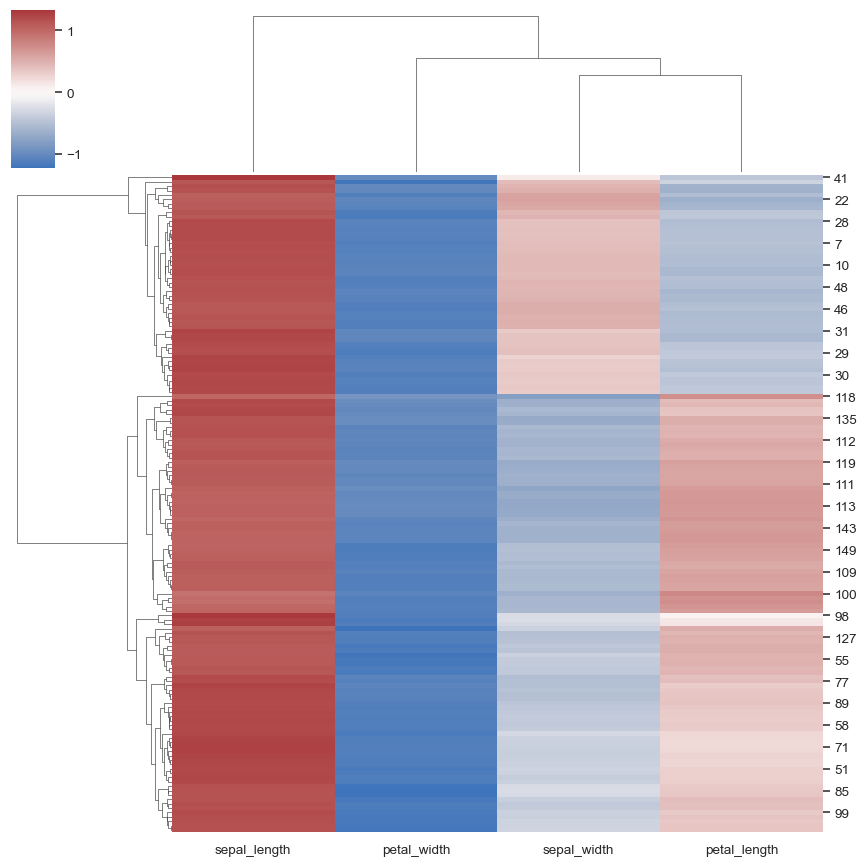
iris = sns.load_dataset("iris") species = iris.pop("species") sns.clustermap(iris)
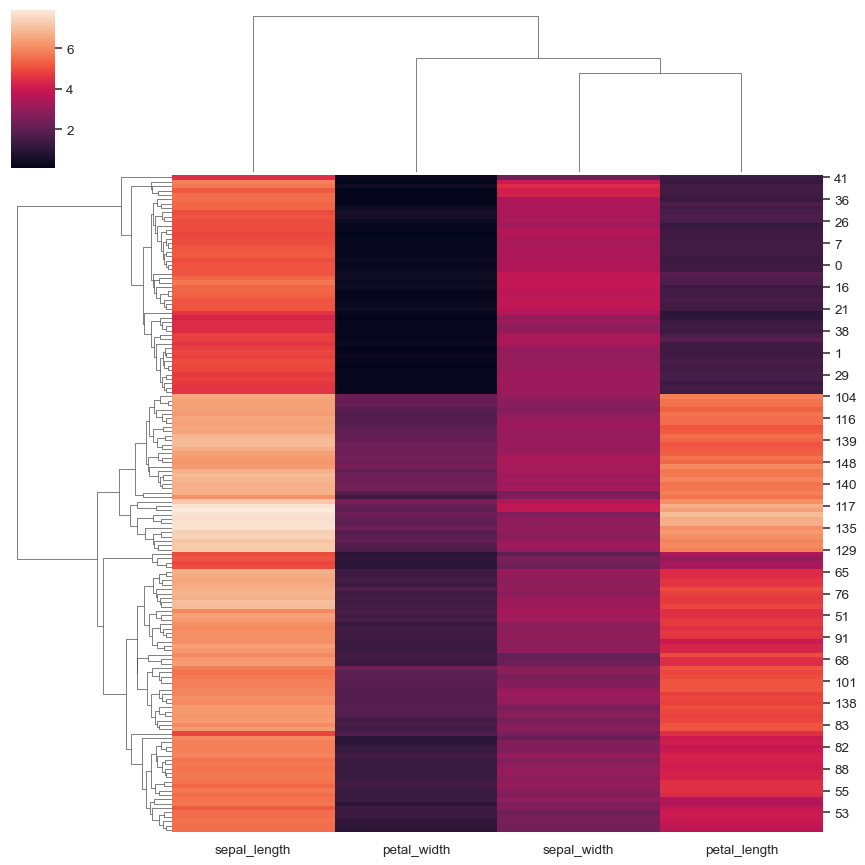
更改图形的大小和布局
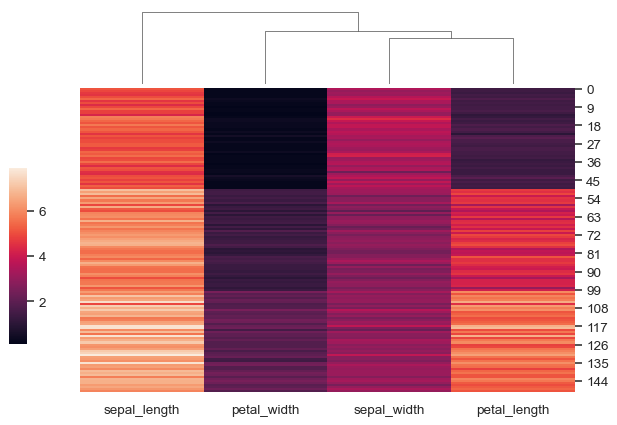
sns.clustermap( iris, figsize=(7, 5), row_cluster=False, dendrogram_ratio=(.1, .2), cbar_pos=(0, .2, .03, .4) )
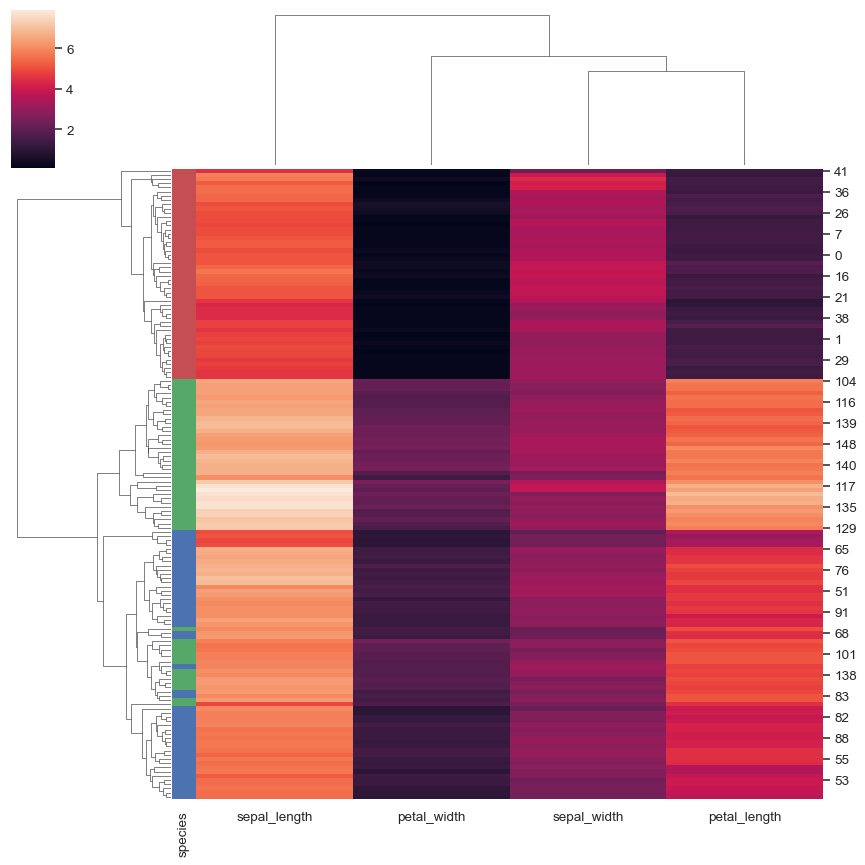
添加彩色标签以识别观测值
lut = dict(zip(species.unique(), "rbg")) row_colors = species.map(lut) sns.clustermap(iris, row_colors=row_colors)
使用不同的颜色映射并调整颜色范围的限制
sns.clustermap(iris, cmap="mako", vmin=0, vmax=10)
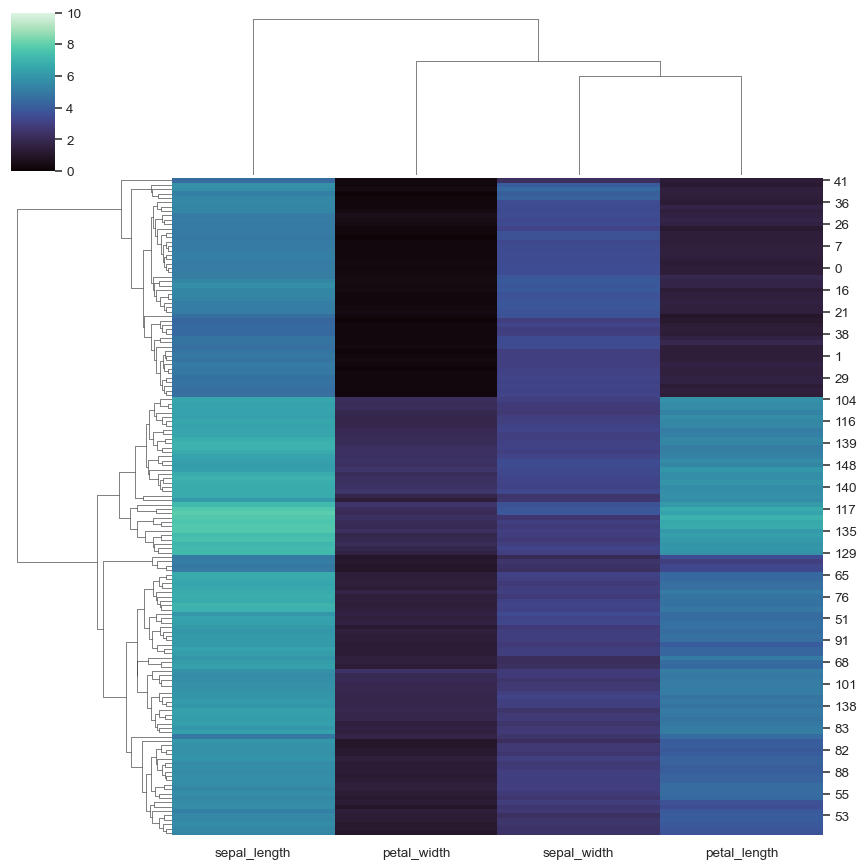
使用不同的聚类参数
sns.clustermap(iris, metric="correlation", method="single")
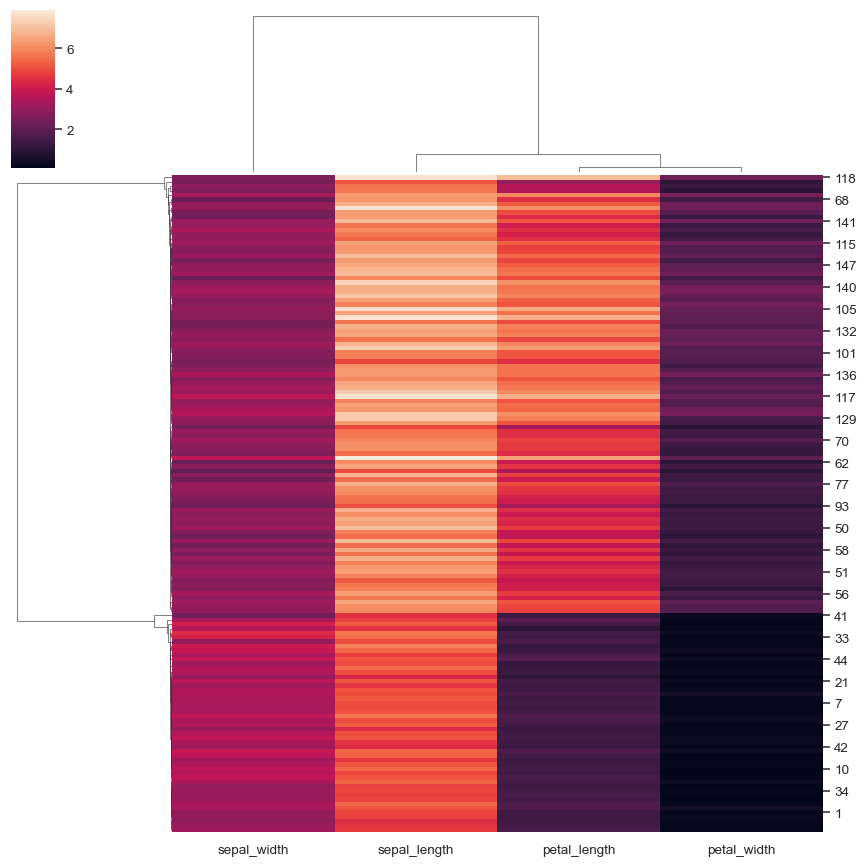
对列中的数据进行标准化
sns.clustermap(iris, standard_scale=1)
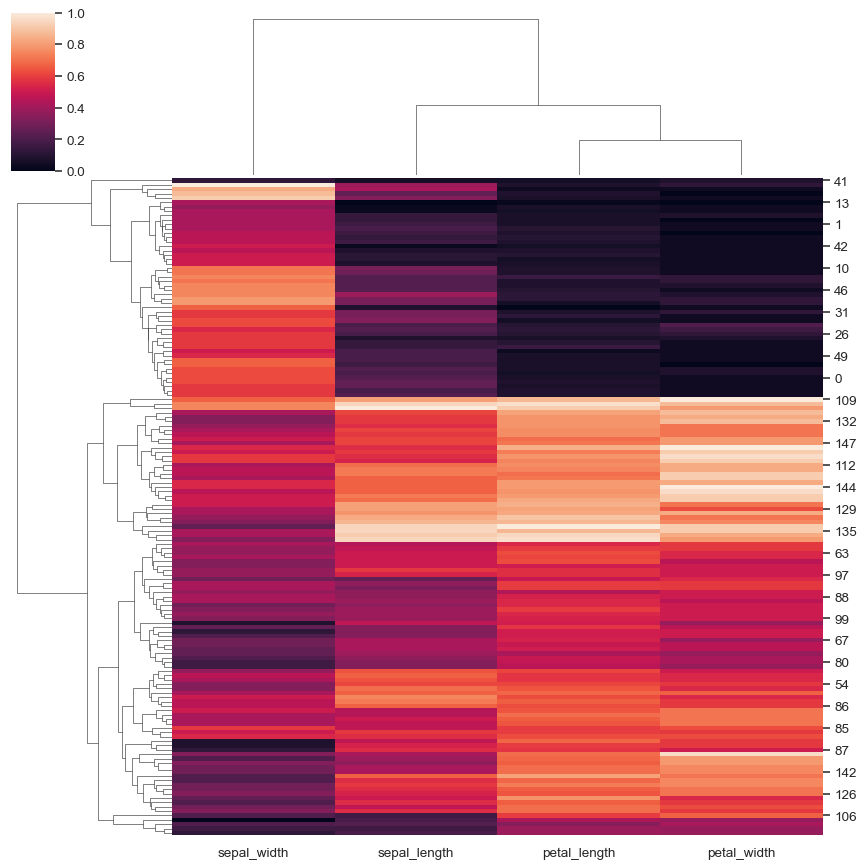
对行中的数据进行归一化
sns.clustermap(iris, z_score=0, cmap="vlag", center=0)