seaborn.objects.KDE#
- class seaborn.objects.KDE(bw_adjust=1, bw_method='scott', common_norm=True, common_grid=True, gridsize=200, cut=3, cumulative=False)#
计算单变量核密度估计。
- 参数:
- bw_adjustfloat
乘法缩放使用
bw_method选择的值的因子。增加将使曲线更平滑。参见 Notes。- bw_method字符串、标量或可调用对象
用于确定要使用的平滑带宽的方法。直接传递给
scipy.stats.gaussian_kde; 在那里查看选项。- common_norm布尔值或变量列表
如果
True,则归一化,使所有曲线的面积之和为 1。如果False,则独立归一化每条曲线。如果为列表,则定义要分组和在其中归一化的变量。- common_grid布尔值或变量列表
如果
True,则所有曲线将共享相同的评估网格。如果False,则每个评估网格都是独立的。如果为列表,则定义要分组并在其中共享网格的变量。- gridsize整数或 None
评估网格中的点数。如果为 None,则在原始数据点处评估密度。
- cut浮点数
因子,乘以核带宽,决定评估网格延伸到极端数据点之外的距离。当设置为 0 时,曲线在数据限制处被截断。
- cumulative布尔值
如果为 True,则估计累积分布函数。需要 scipy。
Notes
带宽或平滑核的标准差是一个重要参数。与直方图箱宽非常相似,使用错误的带宽会导致扭曲的表示。过度平滑会抹去真实特征,而过度平滑会创建虚假特征。默认值使用适用于大致呈钟形分布的分布的经验法则。建议通过更改
bw_adjust来检查默认值。由于平滑是使用高斯核进行的,因此估计的密度曲线可以扩展到可能没有意义的值。例如,当自然为正的数据时,曲线可能会在负值上绘制。可以使用
cut参数控制评估范围,但具有许多接近自然边界的观测值的数据集可能更适合使用不同的方法。当数据集自然离散或“尖峰”(包含许多重复的相同值的观测值)时,可能会出现类似的扭曲。KDE 始终会产生平滑曲线,这可能具有误导性。
密度轴上的单位是混淆的常见来源。虽然核密度估计会产生概率分布,但曲线在每个点的高度给出的是密度,而不是概率。只有通过在范围内积分密度才能获得概率。曲线被归一化,以便所有可能值的积分等于 1,这意味着密度轴的刻度取决于数据值。
如果安装了 scipy,将使用其 cython 加速的实现。
示例
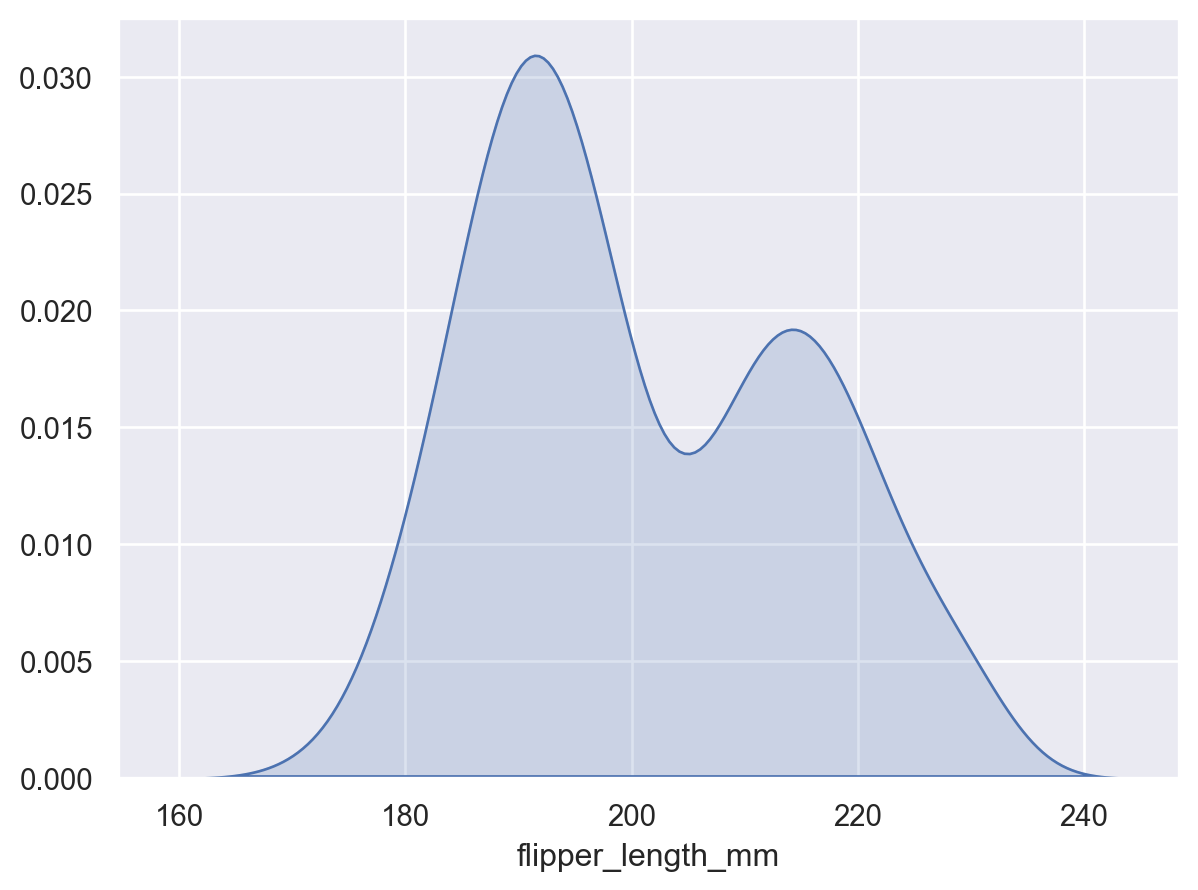
此统计量估计将观测值转换为平滑函数,表示估计的密度
p = so.Plot(penguins, x="flipper_length_mm") p.add(so.Area(), so.KDE())
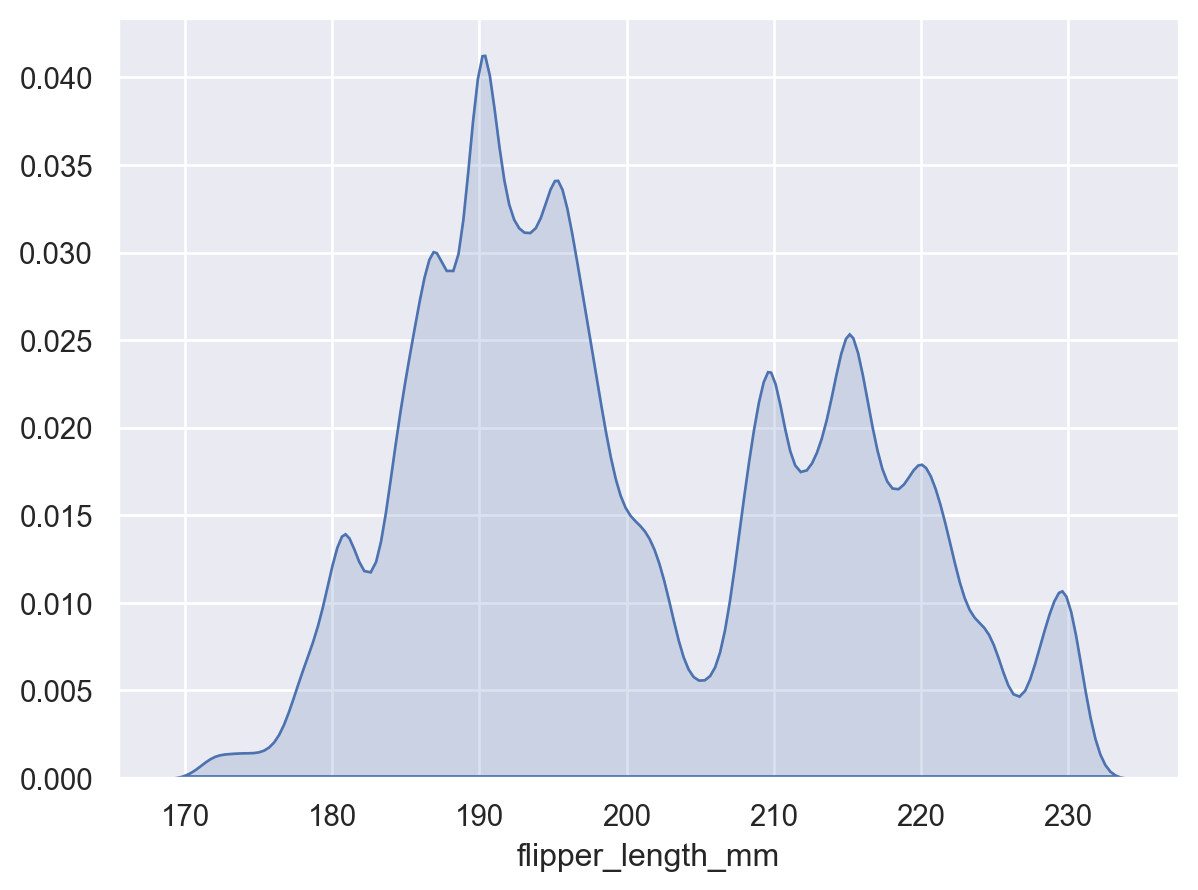
调整平滑带宽以查看更多或更少的细节
p.add(so.Area(), so.KDE(bw_adjust=0.25))
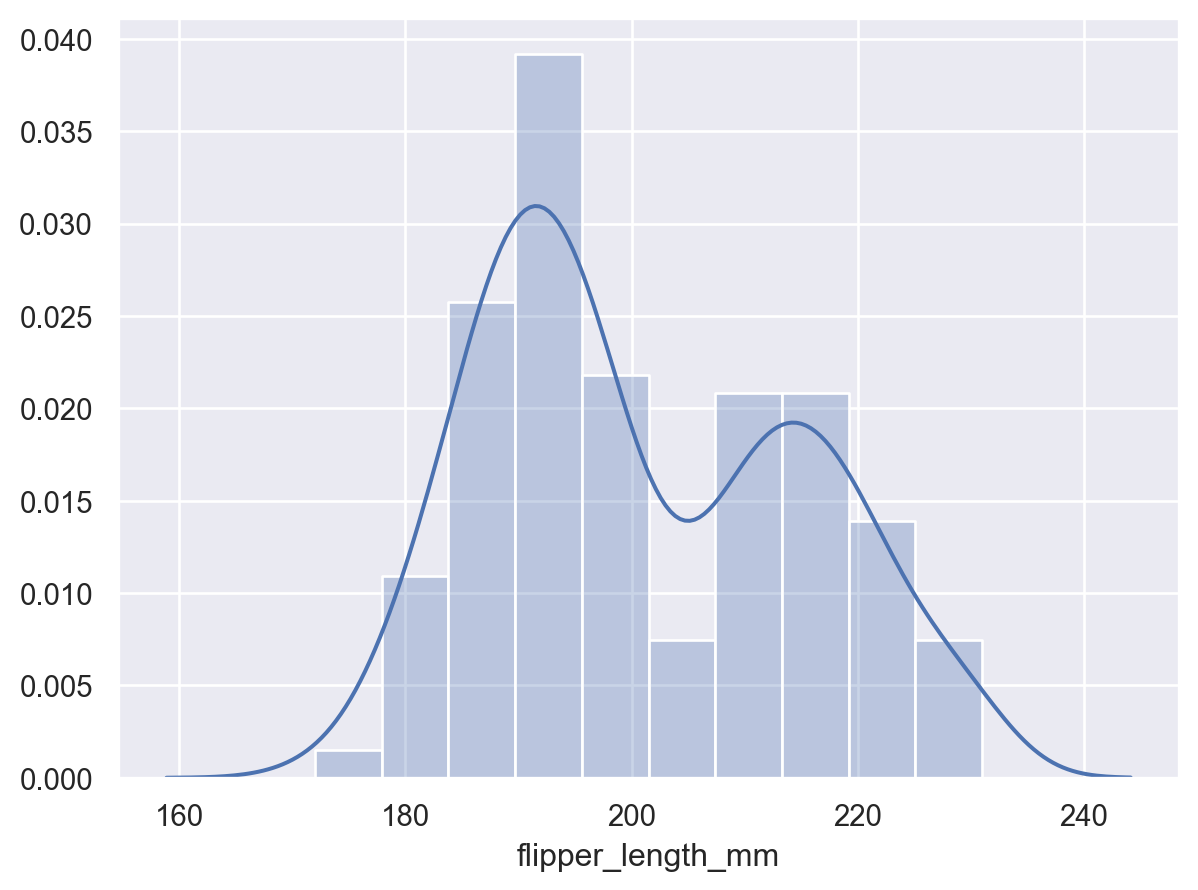
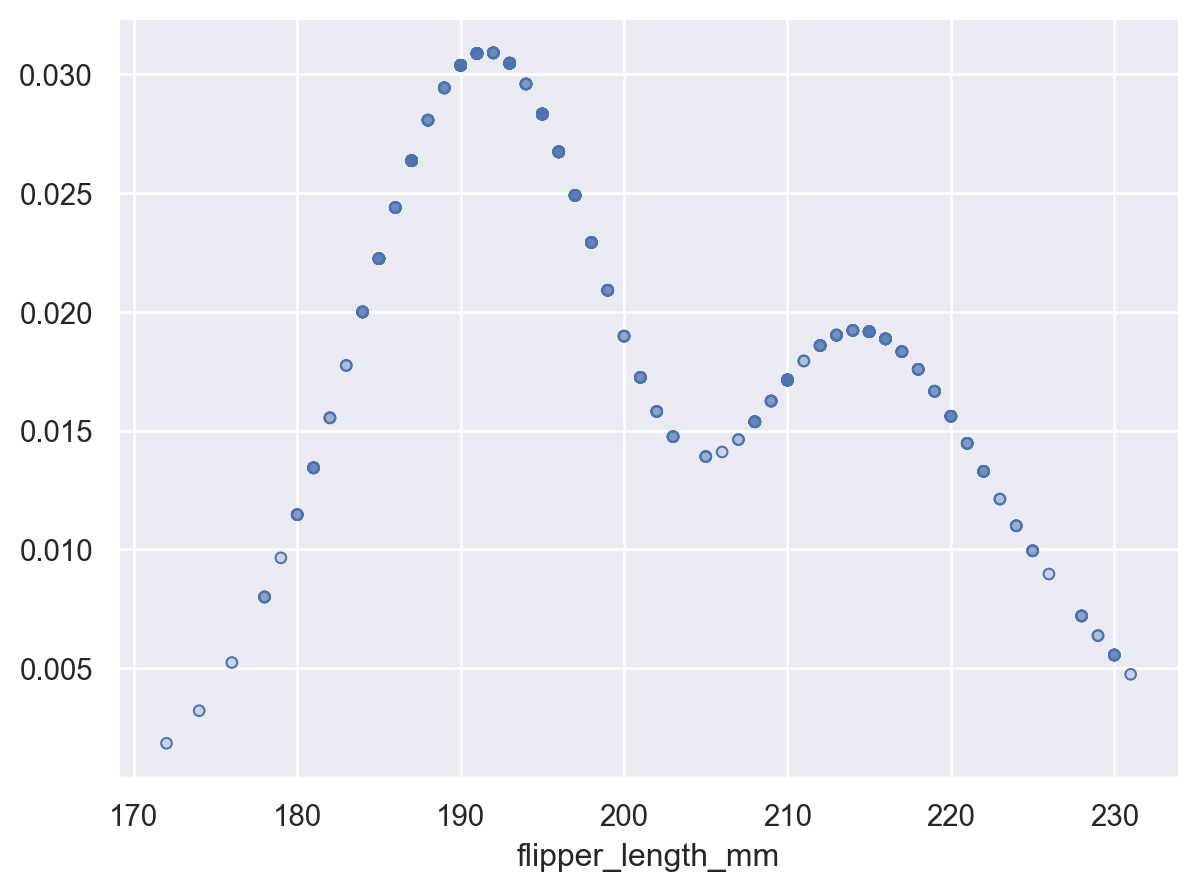
曲线将扩展到数据集中的观测值之外
p2 = p.add(so.Bars(alpha=.3), so.Hist("density")) p2.add(so.Line(), so.KDE())
使用
cut控制密度曲线相对于观测值的范围p2.add(so.Line(), so.KDE(cut=0))
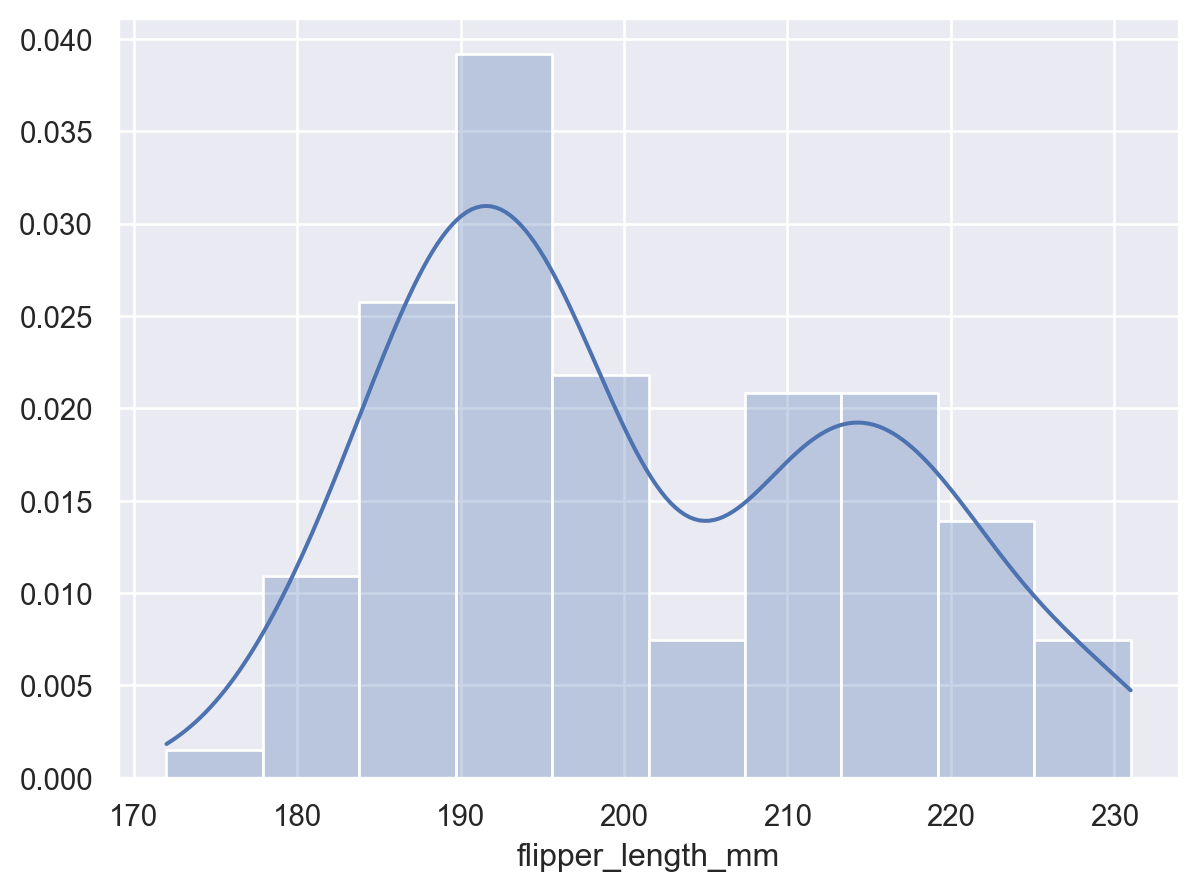
当将观测值分配给
y变量时,将显示x的密度so.Plot(penguins, y="flipper_length_mm").add(so.Area(), so.KDE())
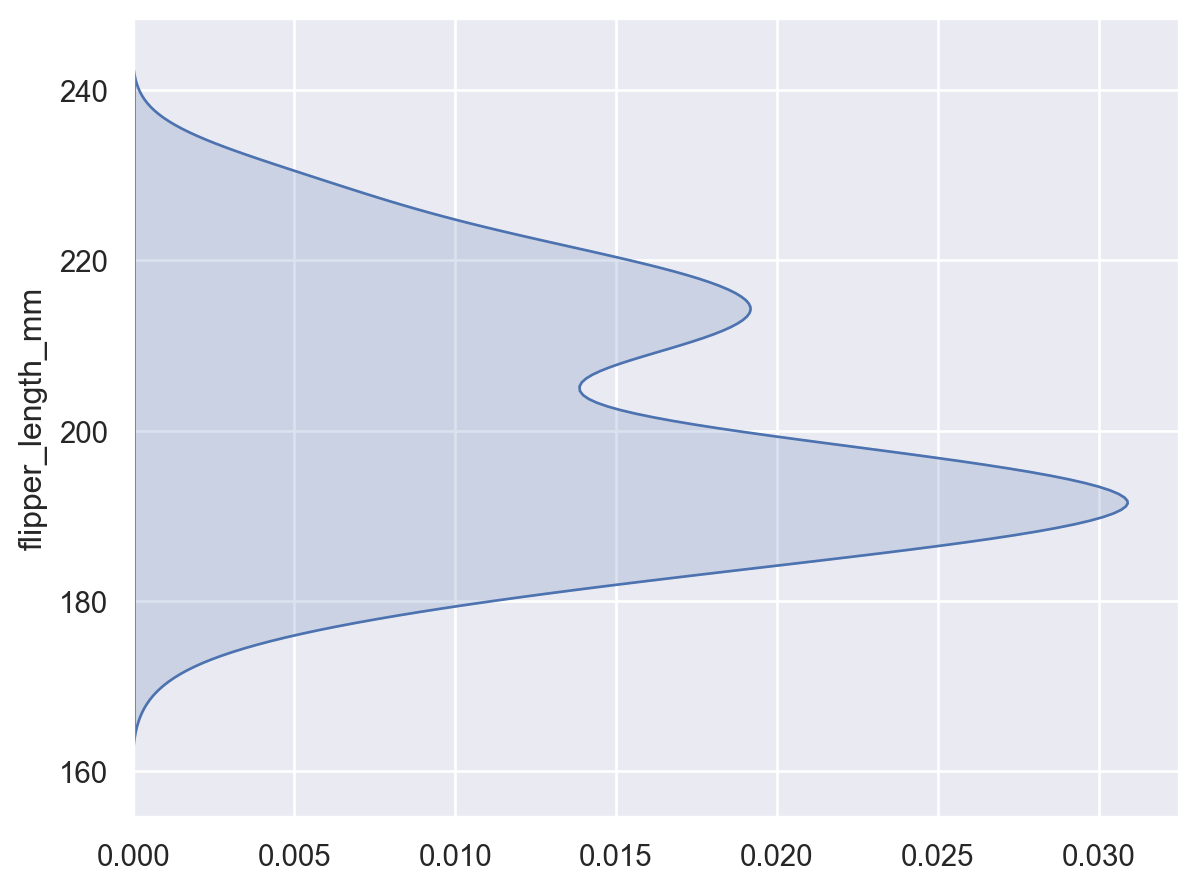
使用
gridsize增加或减少评估密度的网格分辨率p.add(so.Dots(), so.KDE(gridsize=100))
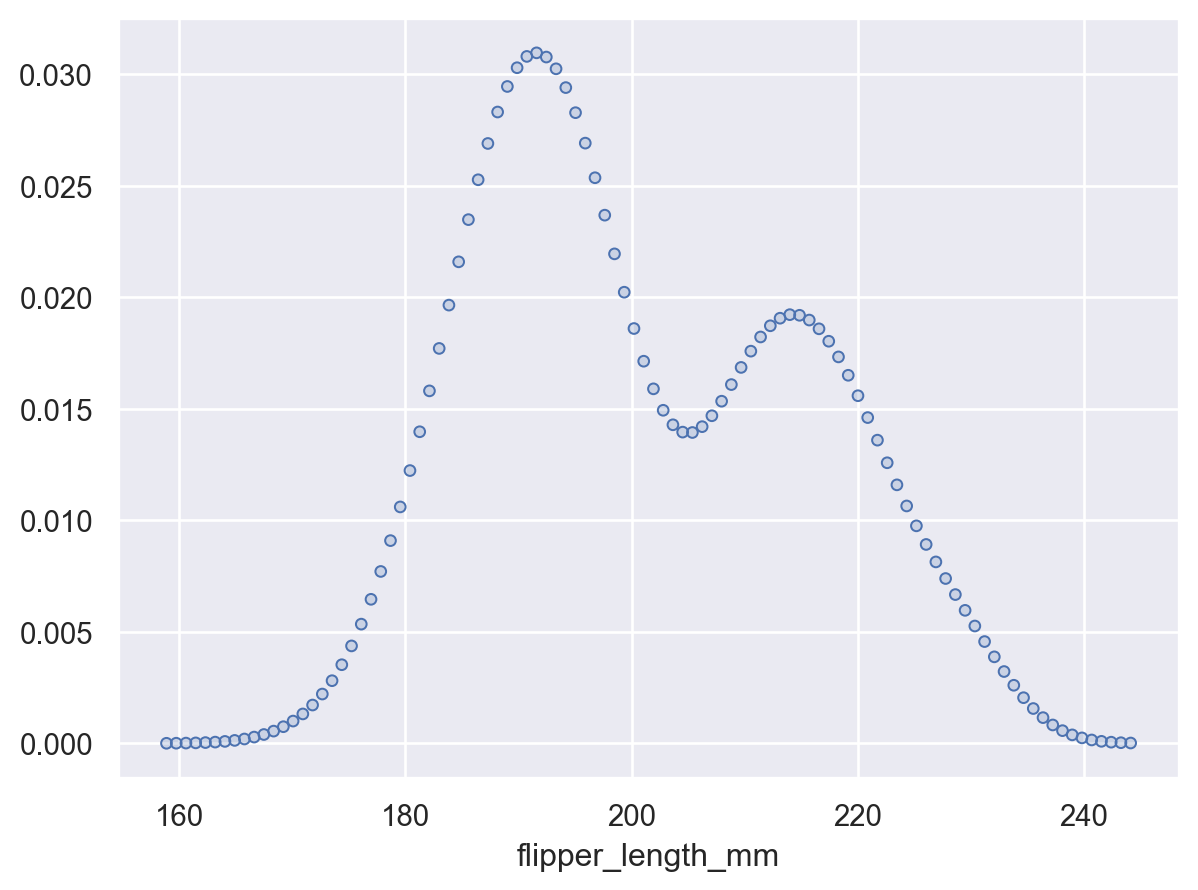
或者传递
None以在原始数据点处评估密度p.add(so.Dots(), so.KDE(gridsize=None))
其他变量将定义估计的组
p.add(so.Area(), so.KDE(), color="species")
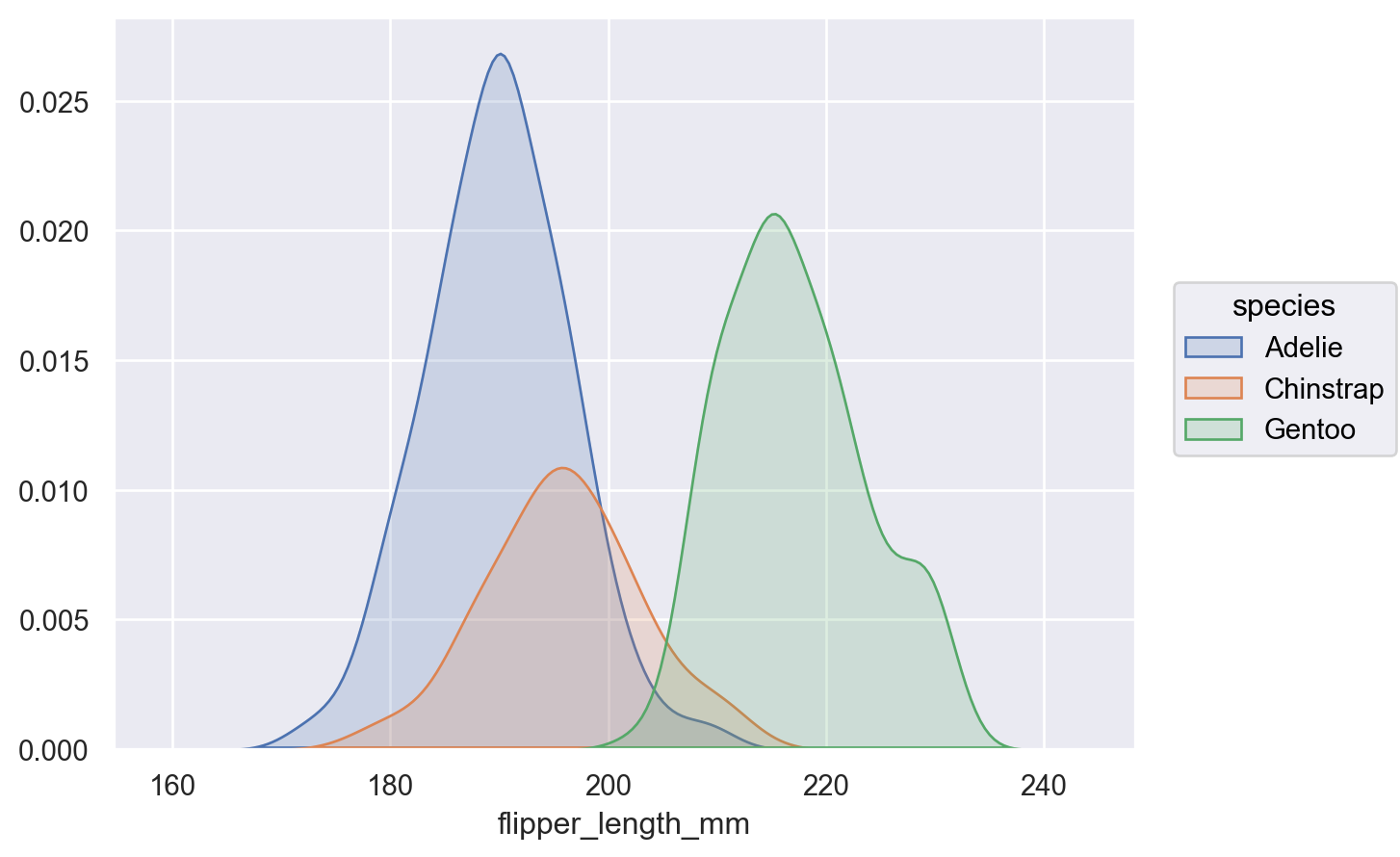
默认情况下,密度在所有组中被归一化(即,显示联合密度);传递
common_norm=False以显示条件密度p.add(so.Area(), so.KDE(common_norm=False), color="species")
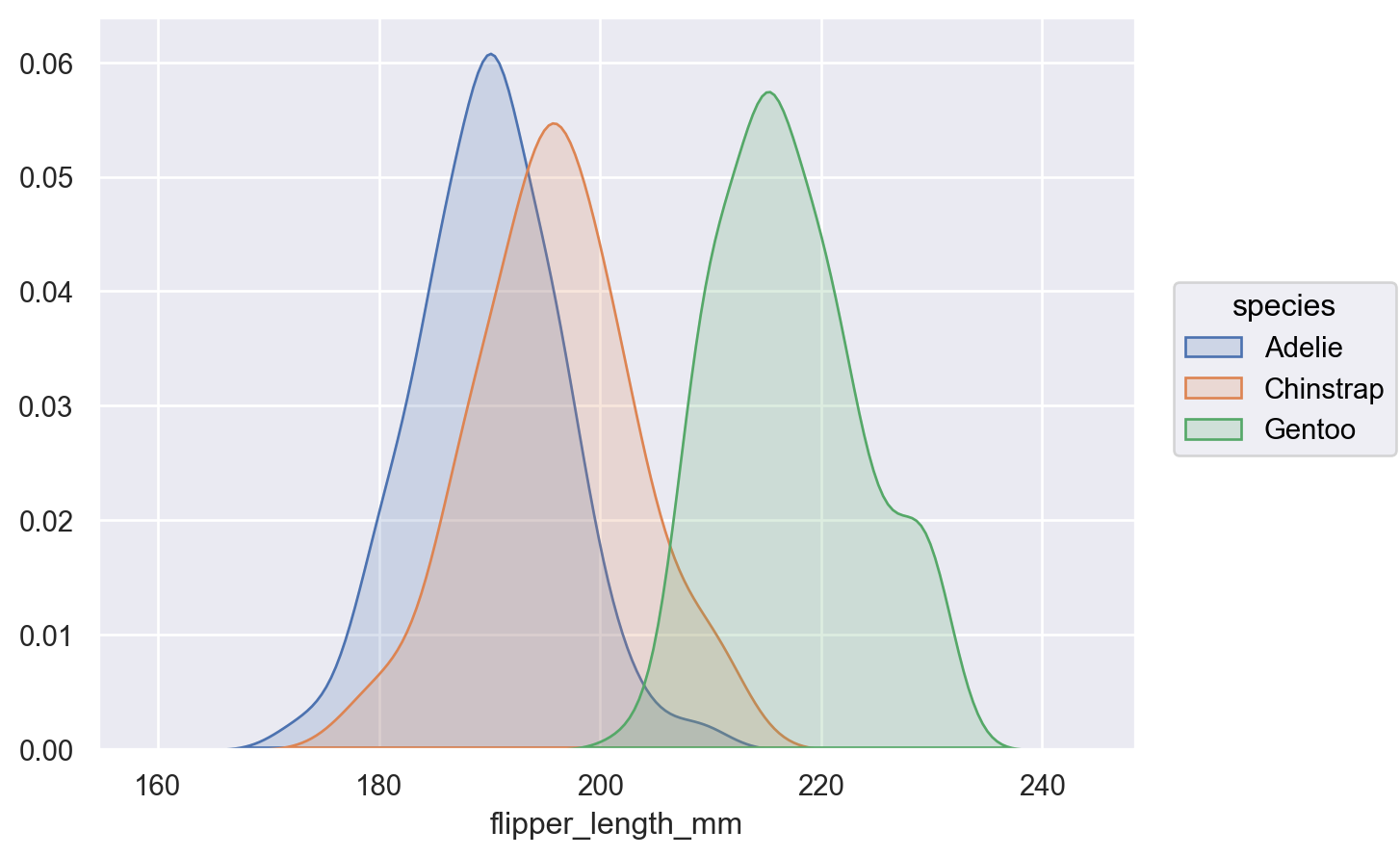
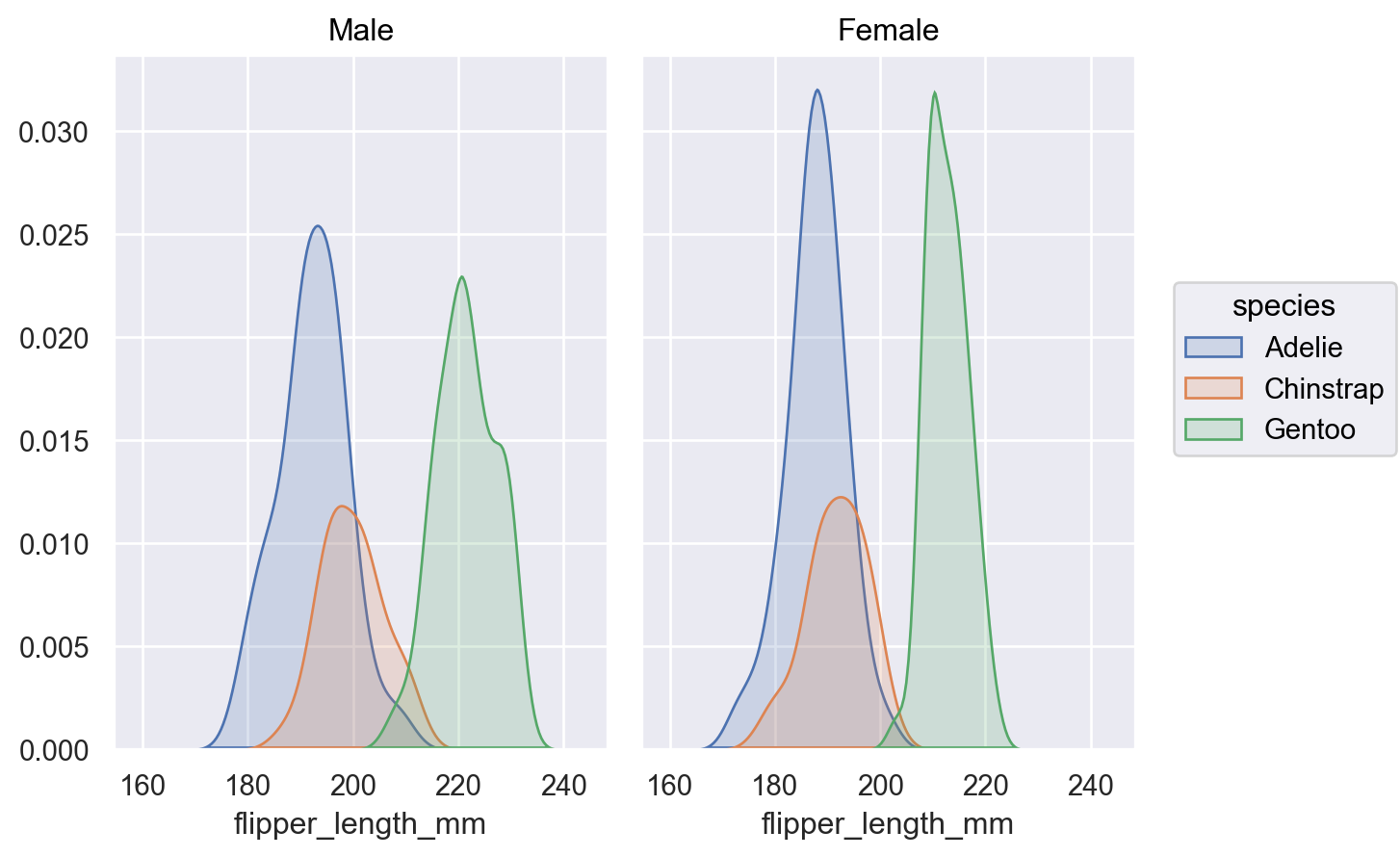
或者传递一个变量列表以作为条件
( p.facet("sex") .add(so.Area(), so.KDE(common_norm=["col"]), color="species") )
此统计量可以与其他转换结合使用,例如
Stack(当common_grid=True时)p.add(so.Area(), so.KDE(), so.Stack(), color="sex")
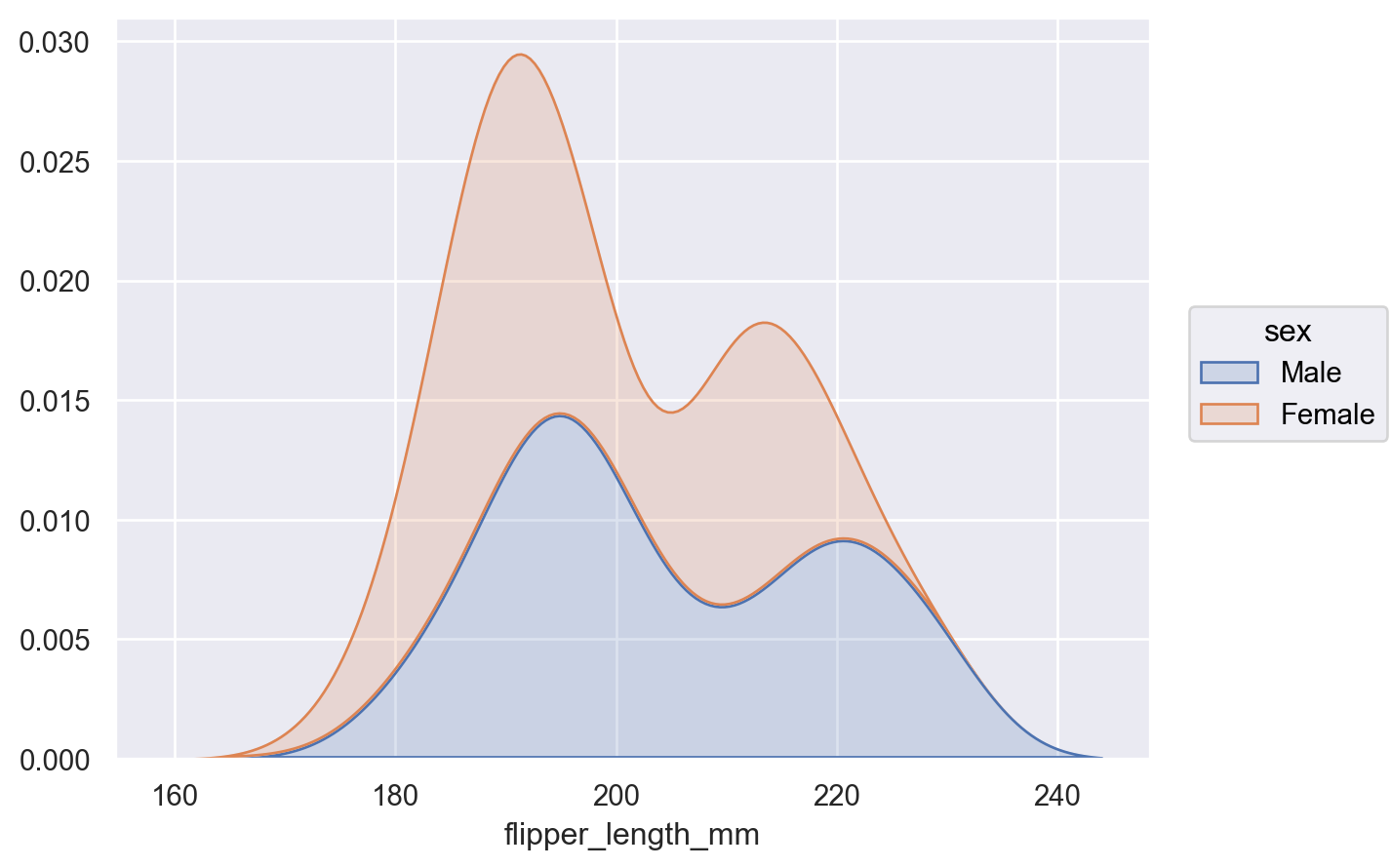
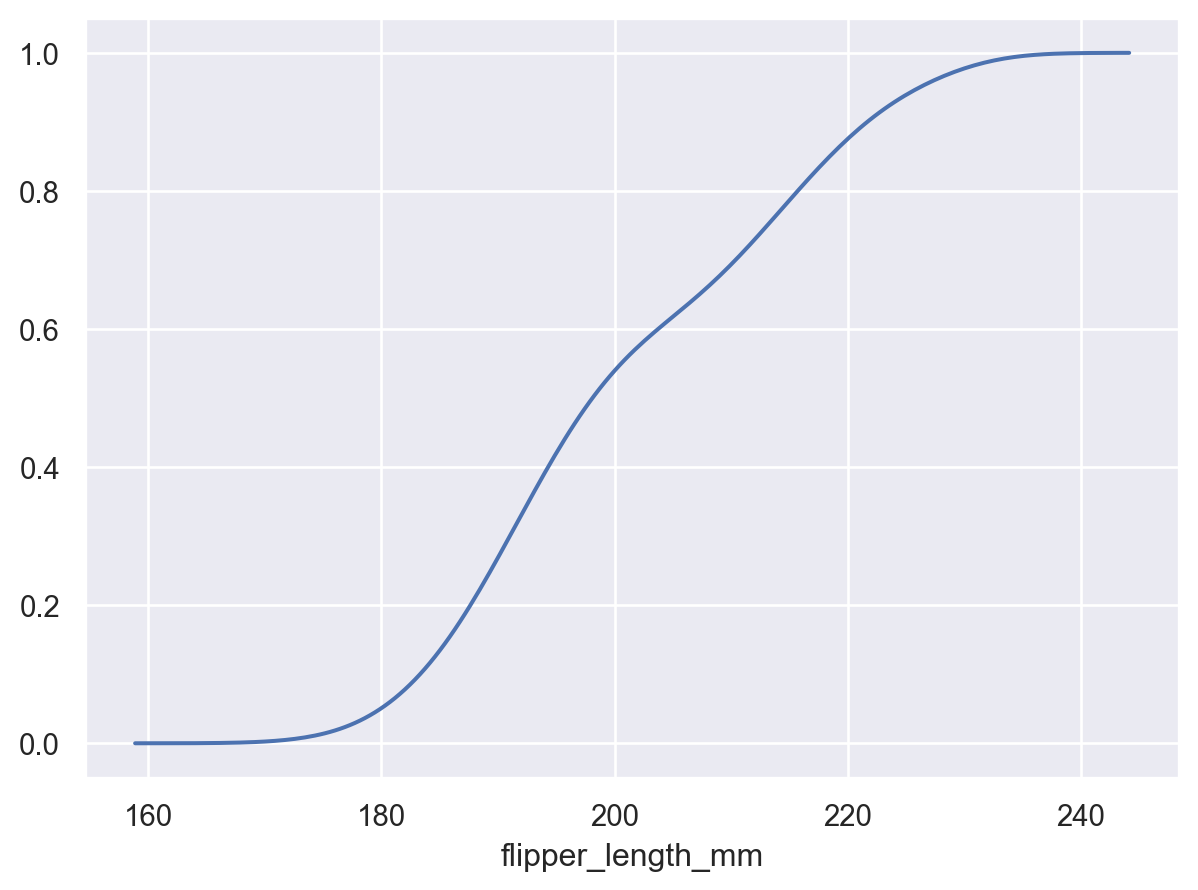
设置
cumulative=True以积分密度p.add(so.Line(), so.KDE(cumulative=True))