seaborn.ecdfplot#
- seaborn.ecdfplot(data=None, *, x=None, y=None, hue=None, weights=None, stat='proportion', complementary=False, palette=None, hue_order=None, hue_norm=None, log_scale=None, legend=True, ax=None, **kwargs)#
绘制经验累积分布函数。
ECDF 表示数据集每个唯一值下方的数据观测值的比例或数量。与直方图或密度图相比,ECDF 的优势在于它可以直接可视化每个观测值,这意味着没有需要调整的 binning 或平滑参数。它还有助于在多个分布之间进行直接比较。缺点是,图的外观与分布的基本属性(如其中心趋势、方差以及是否存在双峰)之间的关系可能不像直观那样清晰。
更多信息请参阅 用户指南.
- 参数:
- data
pandas.DataFrame,numpy.ndarray, 映射或序列 输入数据结构。可以分配给命名变量的长格式向量集合或将在内部重塑的宽格式数据集。
- x, y
data中的向量或键 指定 x 轴和 y 轴上位置的变量。
- hue
data中的向量或键 映射以确定绘图元素颜色的语义变量。
- weights
data中的向量或键 如果提供,请使用这些值来加权相应数据点对累积分布的贡献。
- stat{{“proportion”, “percent”, “count”}}
要计算的分布统计量。
- complementarybool
如果为 True,则使用互补 CDF (1 - CDF)
- palette字符串、列表、字典或
matplotlib.colors.Colormap 用于选择在映射
hue语义时使用的颜色的方法。字符串值将传递给color_palette()。列表或字典值表示分类映射,而颜色图对象表示数值映射。- hue_order字符串向量
指定
hue语义的分类级别的处理和绘图顺序。- hue_norm元组或
matplotlib.colors.Normalize 可以是设置数据单位中归一化范围的一对值,也可以是将数据单位映射到 [0, 1] 区间的对象。使用表示数值映射。
- log_scalebool 或数字,或 bool 或数字对
将轴刻度设置为对数。单个值设置图中任何数值轴的数据轴。一对值独立地设置每个轴。数值被解释为所需的基数(默认值为 10)。当为
None或False时,seaborn 将采用现有的 Axes 刻度。- legendbool
如果为 False,则抑制语义变量的图例。
- ax
matplotlib.axes.Axes 绘图的预先存在的轴。否则,内部调用
matplotlib.pyplot.gca()。- kwargs
其他关键字参数将传递给
matplotlib.axes.Axes.plot()。
- data
- 返回值:
matplotlib.axes.Axes包含绘图的 matplotlib 轴。
另请参阅
示例
在 x 轴上绘制单变量分布
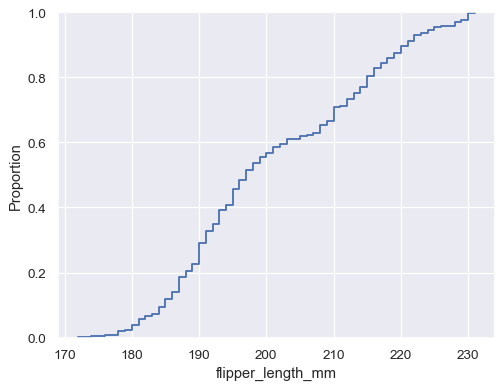
penguins = sns.load_dataset("penguins") sns.ecdfplot(data=penguins, x="flipper_length_mm")
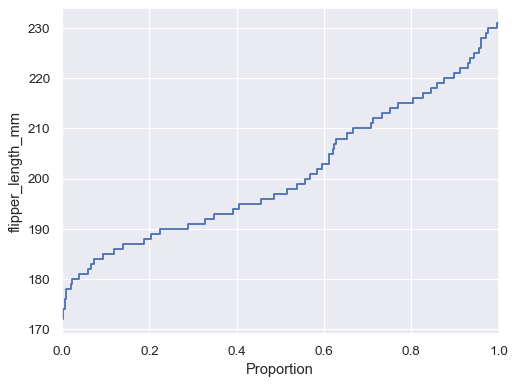
通过将数据变量分配给 y 轴来翻转绘图
sns.ecdfplot(data=penguins, y="flipper_length_mm")
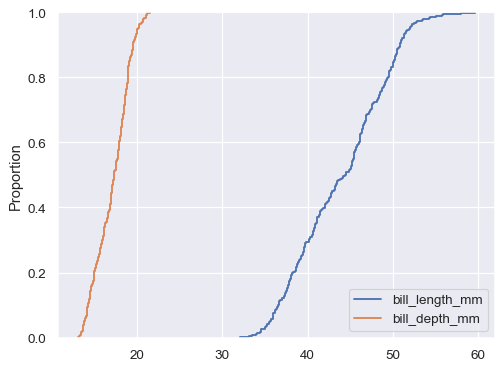
如果既没有分配
x也没有分配y,则数据集将被视为宽格式,并且将为每个数值列绘制直方图sns.ecdfplot(data=penguins.filter(like="bill_", axis="columns"))
您还可以使用色调映射从长格式数据集中绘制多个直方图
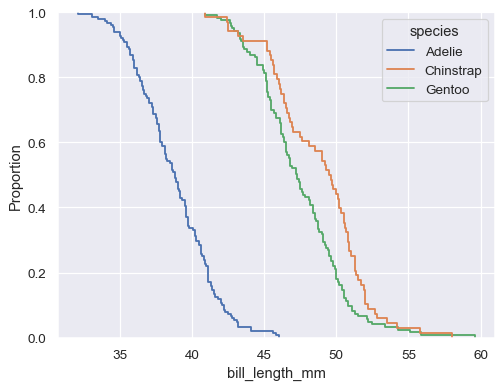
sns.ecdfplot(data=penguins, x="bill_length_mm", hue="species")
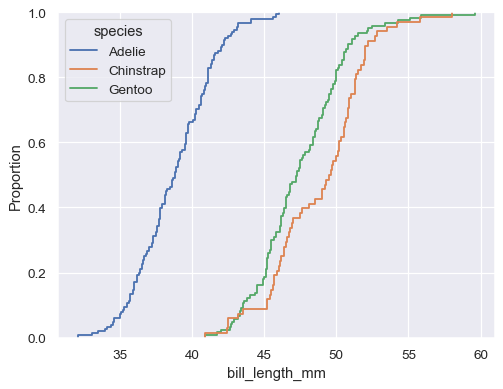
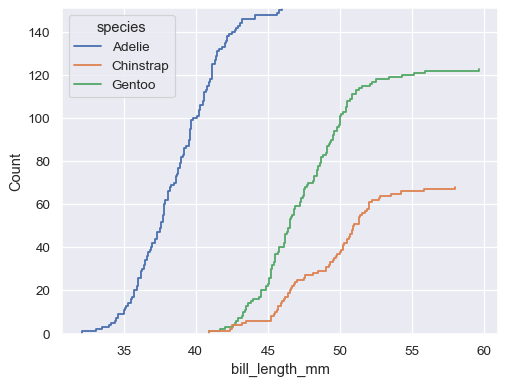
默认分布统计量已归一化以显示比例,但您可以改为显示绝对数量或百分比
sns.ecdfplot(data=penguins, x="bill_length_mm", hue="species", stat="count")
还可以绘制经验互补 CDF (1 - CDF)
sns.ecdfplot(data=penguins, x="bill_length_mm", hue="species", complementary=True)