seaborn.lineplot#
- seaborn.lineplot(data=None, *, x=None, y=None, hue=None, size=None, style=None, units=None, weights=None, palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None, size_norm=None, dashes=True, markers=None, style_order=None, estimator='mean', errorbar=('ci', 95), n_boot=1000, seed=None, orient='x', sort=True, err_style='band', err_kws=None, legend='auto', ci='deprecated', ax=None, **kwargs)#
绘制一条线,并可以进行多个语义分组。
可以使用
hue、size和style参数显示数据不同子集之间x和y之间的关系。这些参数控制使用哪些视觉语义来识别不同的子集。可以使用所有三种语义类型独立地显示最多三个维度,但这种类型的绘图可能难以解释,而且通常效果不佳。使用冗余语义(例如,对同一个变量使用hue和style)有助于使图形更容易理解。有关更多信息,请参见 教程。
默认情况下,
hue(以及在较小程度上,size)语义的处理方式取决于推断的变量是代表“数值”数据还是“分类”数据。具体来说,数值变量默认情况下使用顺序色图表示,图例条目显示具有值的有规律的“刻度”,这些值可能存在于数据中,也可能不存在。这种行为可以通过各种参数来控制,如下所述并举例说明。默认情况下,该图在每个
x值的多个y值上进行聚合,并显示该估计的中心趋势和置信区间。- 参数:
- data
pandas.DataFrame,numpy.ndarray, 映射或序列 输入数据结构。可以分配给命名变量的向量集合或将内部重新整形为宽格式数据集。
- x, y向量或
data中的键 指定 x 轴和 y 轴位置的变量。
- hue向量或
data中的键 分组变量,将生成具有不同颜色的线。可以是分类变量,也可以是数值变量,但颜色映射在后一种情况下将表现不同。
- size向量或
data中的键 分组变量,将生成具有不同宽度的线。可以是分类变量,也可以是数值变量,但大小映射在后一种情况下将表现不同。
- style向量或
data中的键 分组变量,将生成具有不同虚线和/或标记的线。可以具有数值数据类型,但始终被视为分类变量。
- units向量或
data中的键 标识采样单位的分组变量。使用时,将为每个单元绘制一条单独的线,并具有相应的语义,但不会添加图例条目。当不需要确切身份时,这对于显示实验重复的分布很有用。
- weights向量或
data中的键 用于计算加权估计的数据值或列。请注意,当前使用权重将统计量的选择限制为“平均值”估计量和“ci”误差条。
- palette字符串、列表、字典或
matplotlib.colors.Colormap 用于选择映射
hue语义时使用的颜色的方法。字符串值将传递给color_palette()。列表或字典值意味着分类映射,而颜色映射对象意味着数值映射。- hue_order字符串向量
指定
hue语义的分类级别的处理和绘图顺序。- hue_norm元组或
matplotlib.colors.Normalize 数据单位中的一对值,用于设置归一化范围,或一个对象,用于将数据单位映射到 [0, 1] 区间。用法意味着数值映射。
- sizes列表、字典或元组
一个对象,用于确定在使用
size时如何选择大小。列表或字典参数应为每个唯一数据值提供一个大小,这将强制进行分类解释。该参数也可以是最小值、最大值元组。- size_order列表
指定
size变量级别的外观顺序,否则它们将从数据中确定。当size变量为数值时,与之无关。- size_norm元组或 Normalize 对象
当
size变量为数值时,用于缩放绘图对象的 data 单位的归一化。- dashes布尔值、列表或字典
对象,用于确定如何绘制
style变量的不同级别的线条。设置为True将使用默认虚线代码,或者您可以传递一个虚线代码列表或一个字典,将style变量的级别映射到虚线代码。设置为False将对所有子集使用实线。虚线在 matplotlib 中指定:(segment, gap)长度的元组,或一个空字符串,用于绘制实线。- markers布尔值、列表或字典
对象,用于确定如何绘制
style变量的不同级别的标记。设置为True将使用默认标记,或者您可以传递一个标记列表或一个字典,将style变量的级别映射到标记。设置为False将绘制无标记的线条。标记在 matplotlib 中指定。- style_order列表
指定
style变量级别的外观顺序,否则它们将从数据中确定。当style变量为数值时,与之无关。- estimatorpandas 方法的名称或可调用对象或 None
在相同
x级别上跨多个y变量观测值的聚合方法。如果为None,则将绘制所有观测值。- errorbar字符串、(字符串、数字) 元组或可调用对象
误差条方法的名称(“ci”、“pi”、“se”或“sd”),或包含方法名称和级别参数的元组,或从向量映射到 (最小值,最大值) 区间的函数,或 None 以隐藏误差条。有关更多信息,请参阅 误差条教程。
- n_boot整数
用于计算置信区间的自举次数。
- seed整数、numpy.random.Generator 或 numpy.random.RandomState
用于可重复自举的种子或随机数生成器。
- orient“x” 或 “y”
数据排序/聚合的维度。等效地,结果函数的“自变量”。
- sort布尔值
如果为 True,则数据将按 x 和 y 变量排序,否则线条将按它们在数据集中出现的顺序连接点。
- err_style“band” 或 “bars”
是否使用半透明误差带或离散误差条来绘制置信区间。
- err_kws关键字参数字典
控制误差条的美学外观的其他参数。kwargs 传递给
matplotlib.axes.Axes.fill_between()或matplotlib.axes.Axes.errorbar(),具体取决于err_style。- legend“auto”, “brief”, “full”, 或 False
如何绘制图例。如果为 “brief”,则数值
hue和size变量将使用均匀间隔值的样本进行表示。如果为 “full”,则每个组将在图例中获得一个条目。如果为 “auto”,则根据级别数量在简短或完整表示之间进行选择。如果为False,则不添加图例数据,也不绘制图例。- ci整数或 “sd” 或 None
聚合时绘制的置信区间的尺寸。
自版本 0.12.0 起弃用: 使用新的
errorbar参数以获得更大的灵活性。- ax
matplotlib.axes.Axes 绘图的预先存在的轴。否则,在内部调用
matplotlib.pyplot.gca()。- kwargs键值映射
其他关键字参数将传递给
matplotlib.axes.Axes.plot()。
- data
- 返回值:
matplotlib.axes.Axes包含绘图的 matplotlib 轴。
另请参阅
scatterplot使用点绘制数据。
pointplot使用标记和线条绘制点估计值和 CI。
示例
flights数据集包含 10 年的每月航空乘客数据flights = sns.load_dataset("flights") flights.head()
年 月 乘客 0 1949 一月 112 1 1949 二月 118 2 1949 三月 132 3 1949 四月 129 4 1949 五月 121 要使用长格式数据绘制折线图,请分配
x和y变量may_flights = flights.query("month == 'May'") sns.lineplot(data=may_flights, x="year", y="passengers")
将数据框透视到宽格式表示
flights_wide = flights.pivot(index="year", columns="month", values="passengers") flights_wide.head()
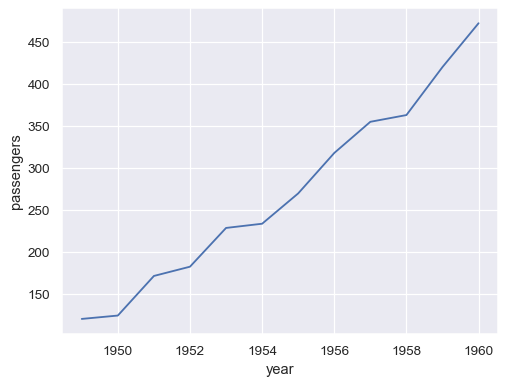
月 一月 二月 三月 四月 五月 六月 七月 八月 九月 十月 十一月 十二月 年 1949 112 118 132 129 121 135 148 148 136 119 104 118 1950 115 126 141 135 125 149 170 170 158 133 114 140 1951 145 150 178 163 172 178 199 199 184 162 146 166 1952 171 180 193 181 183 218 230 242 209 191 172 194 1953 196 196 236 235 229 243 264 272 237 211 180 201 要绘制单个向量,请将其传递给
data。如果向量是pandas.Series,则它将针对其索引绘制sns.lineplot(data=flights_wide["May"])
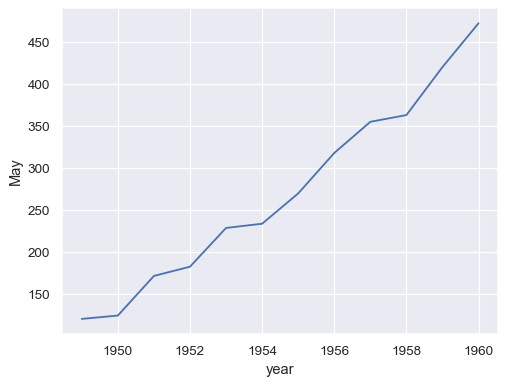
将整个宽格式数据集传递给
data将为每一列绘制一条单独的线条sns.lineplot(data=flights_wide)
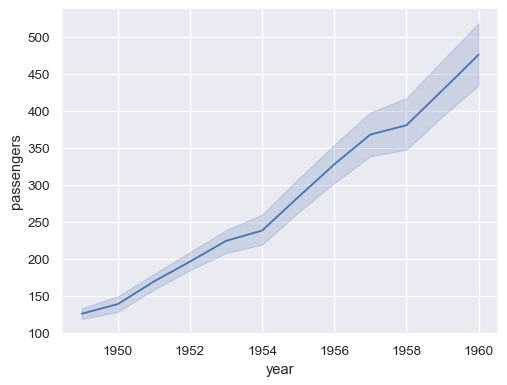
将整个数据集以长格式模式传递将对重复值(每年)进行聚合,以显示平均值和 95% 置信区间
sns.lineplot(data=flights, x="year", y="passengers")
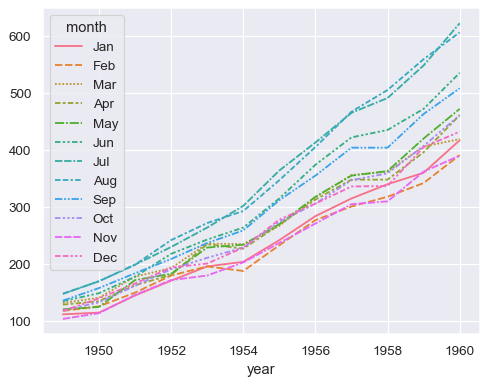
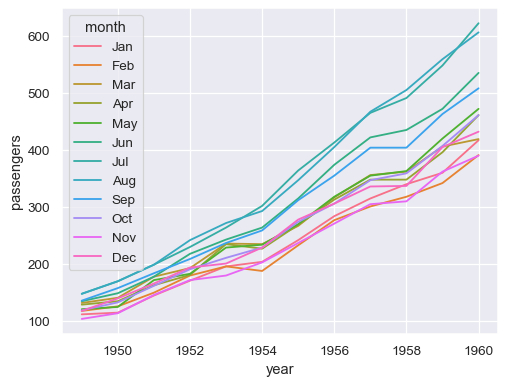
分配一个分组语义(
hue、size或style)以绘制单独的线条sns.lineplot(data=flights, x="year", y="passengers", hue="month")
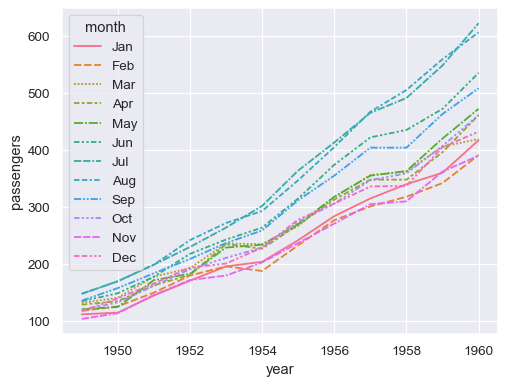
同一列可以分配给多个语义变量,这可以提高绘图的可访问性
sns.lineplot(data=flights, x="year", y="passengers", hue="month", style="month")
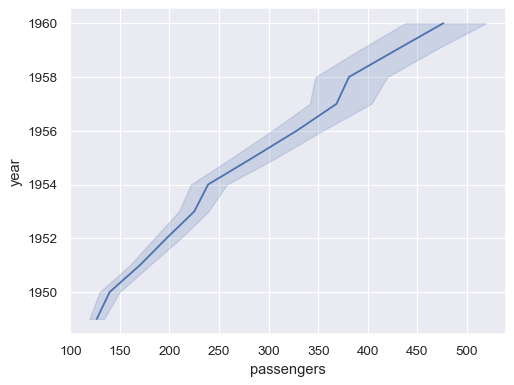
使用
orient参数沿绘图的垂直维度进行聚合和排序sns.lineplot(data=flights, x="passengers", y="year", orient="y")
每个语义变量也可以表示不同的列。为此,我们需要一个更复杂的数据集
fmri = sns.load_dataset("fmri") fmri.head()
受试者 时间点 事件 区域 信号 0 s13 18 刺激 顶叶 -0.017552 1 s5 14 刺激 顶叶 -0.080883 2 s12 18 刺激 顶叶 -0.081033 3 s11 18 刺激 顶叶 -0.046134 4 s10 18 刺激 顶叶 -0.037970 即使使用语义分组,也会对重复观测值进行聚合
sns.lineplot(data=fmri, x="timepoint", y="signal", hue="event")
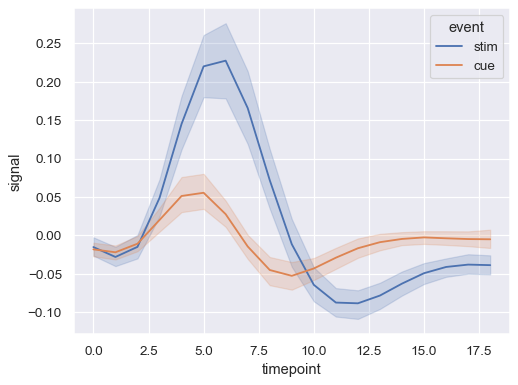
分配
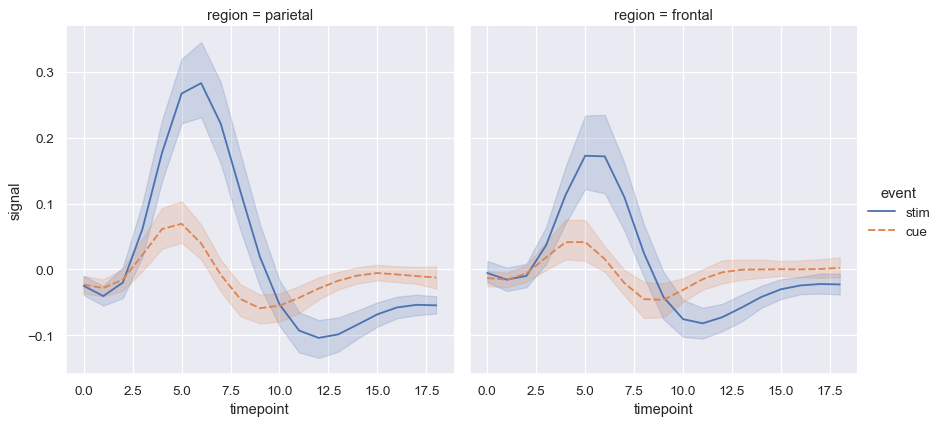
hue和style以表示两个不同的分组变量sns.lineplot(data=fmri, x="timepoint", y="signal", hue="region", style="event")
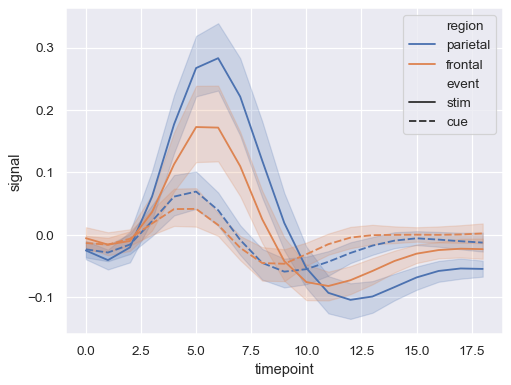
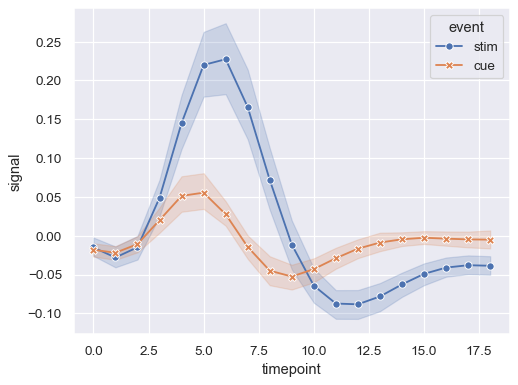
在分配
style变量时,可以使用标记而不是(或与)虚线来区分组sns.lineplot( data=fmri, x="timepoint", y="signal", hue="event", style="event", markers=True, dashes=False )
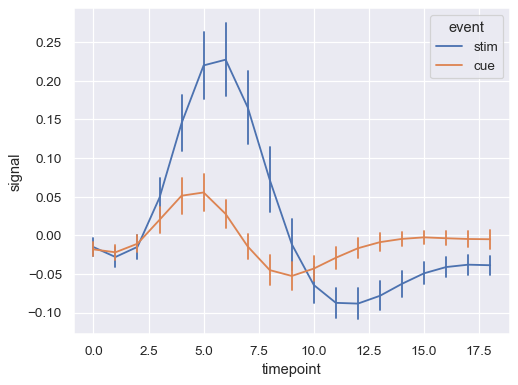
显示误差条而不是误差带,并将它们扩展到两个标准误差宽度
sns.lineplot( data=fmri, x="timepoint", y="signal", hue="event", err_style="bars", errorbar=("se", 2), )
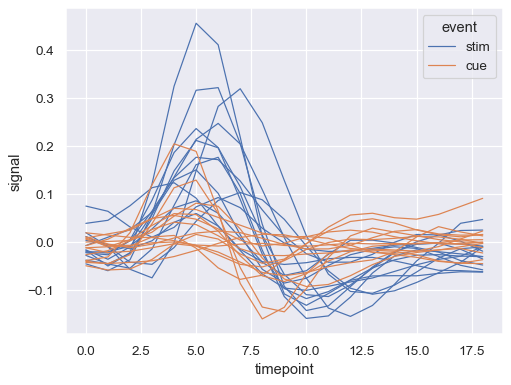
分配
units变量将绘制多条线条,而不应用语义映射sns.lineplot( data=fmri.query("region == 'frontal'"), x="timepoint", y="signal", hue="event", units="subject", estimator=None, lw=1, )
加载另一个具有数值分组变量的数据集
dots = sns.load_dataset("dots").query("align == 'dots'") dots.head()
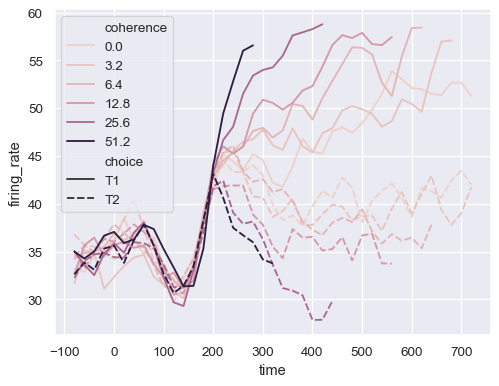
对齐 选择 时间 一致性 放电率 0 点 T1 -80 0.0 33.189967 1 点 T1 -80 3.2 31.691726 2 点 T1 -80 6.4 34.279840 3 点 T1 -80 12.8 32.631874 4 点 T1 -80 25.6 35.060487 将数值变量分配给
hue将以不同的方式映射它,使用不同的默认调色板和定量颜色映射sns.lineplot( data=dots, x="time", y="firing_rate", hue="coherence", style="choice", )
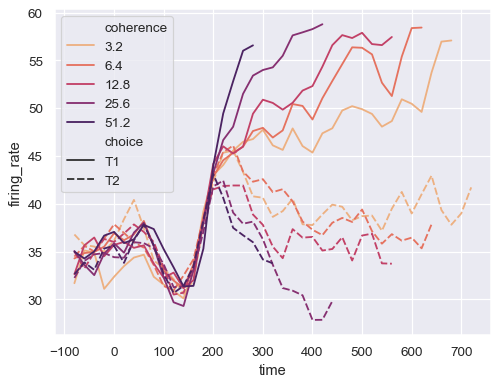
通过设置
palette并传递matplotlib.colors.Normalize对象来控制颜色映射sns.lineplot( data=dots.query("coherence > 0"), x="time", y="firing_rate", hue="coherence", style="choice", palette="flare", hue_norm=mpl.colors.LogNorm(), )
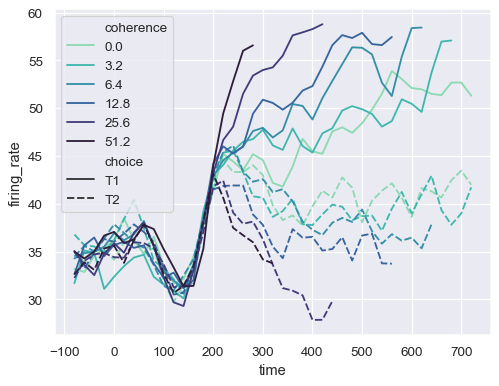
或传递特定的颜色,可以是 Python 列表或字典
palette = sns.color_palette("mako_r", 6) sns.lineplot( data=dots, x="time", y="firing_rate", hue="coherence", style="choice", palette=palette )
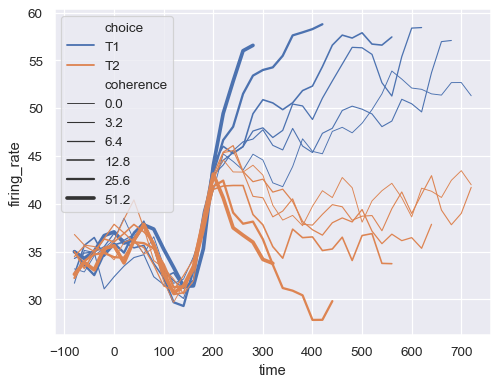
分配
size语义以使用数值变量映射线条的宽度sns.lineplot( data=dots, x="time", y="firing_rate", size="coherence", hue="choice", legend="full" )
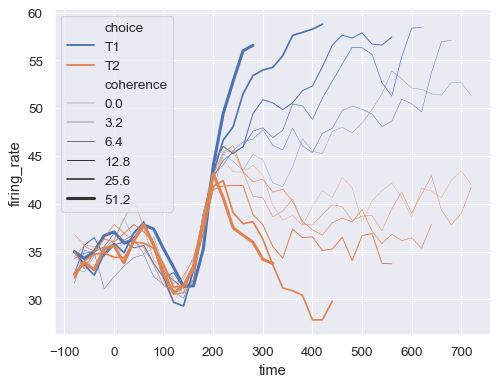
传递一个元组
sizes=(smallest, largest),以控制用于映射size语义的线宽范围sns.lineplot( data=dots, x="time", y="firing_rate", size="coherence", hue="choice", sizes=(.25, 2.5) )
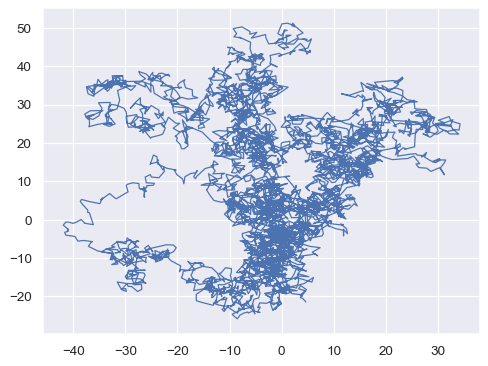
默认情况下,观测值按
x排序。禁用此功能以绘制一条线条,其顺序与观测值在数据集中出现的顺序相同x, y = np.random.normal(size=(2, 5000)).cumsum(axis=1) sns.lineplot(x=x, y=y, sort=False, lw=1)
使用
relplot()来组合lineplot()和FacetGrid。这允许在额外的分类变量中进行分组。使用relplot()比直接使用FacetGrid更安全,因为它确保了语义映射在各个方面的同步。sns.relplot( data=fmri, x="timepoint", y="signal", col="region", hue="event", style="event", kind="line" )